📊 Experiments & Results
Evaluation Setup
Autonomous participation in Machine Learning competitions and R&D tasks.
Benchmarks:
- Weco-Kaggle Lite (16 Tabular ML Competitions) [New]
- MLE-Bench (75 Kaggle Competitions (Deep Learning & Tabular))
- RE-Bench (METR) (AI Research & Development Tasks (e.g., Kernel Optimization))
Metrics:
- Exceeds % of Human (Quantile Performance)
- Medal Rate (Gold/Silver/Bronze)
- Valid Submission Rate
- Statistical methodology: Two-tailed t-test reported for MLE-Bench Lite comparisons (p < 0.01).
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Weco-Kaggle Lite results demonstrating AIDE's superiority over traditional AutoML and generic agents on tabular data. | ||||
| Weco-Kaggle Lite | Exceeds % of Human | 35.34 | 51.38 | +16.04 |
| Weco-Kaggle Lite | Exceeds % of Human | 32.34 | 51.38 | +19.04 |
| MLE-Bench Lite results (from OpenAI's evaluation) showing AIDE's impact when powering state-of-the-art models. | ||||
| MLE-Bench Lite | Any Medal Rate (%) | 7.6 | 36.4 | +28.8 |
| MLE-Bench Lite | Gold Medal Rate (%) | 6.1 | 21.2 | +15.1 |
| MLE-Bench Lite | Valid Submission Rate (%) | 63.6 | 92.4 | +28.8 |
Experiment Figures
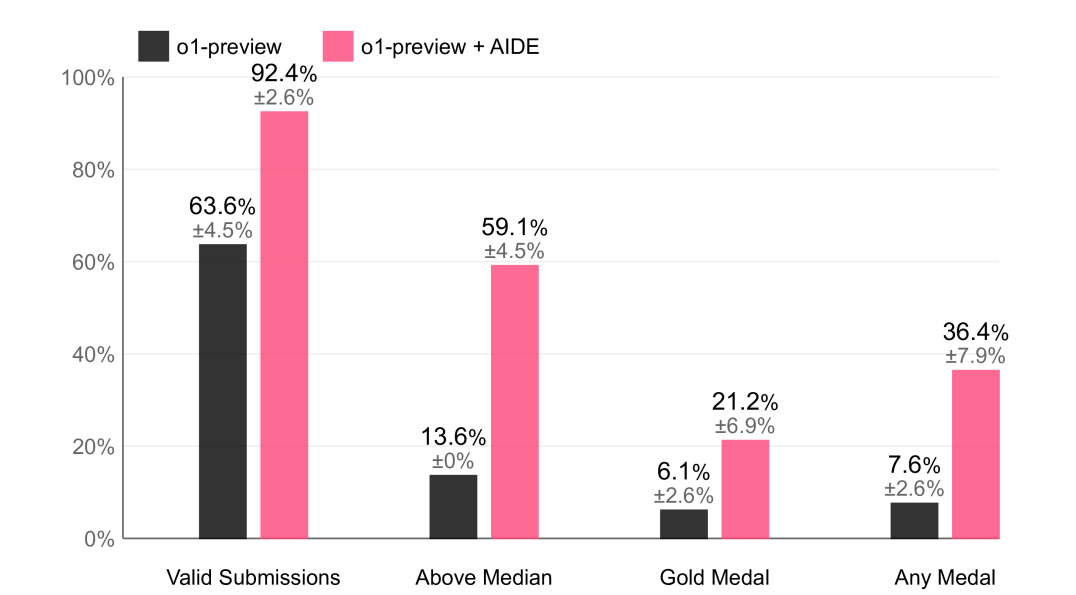
Performance comparison on MLE-Bench Lite between o1-preview alone and AIDE with o1-preview across multiple metrics.
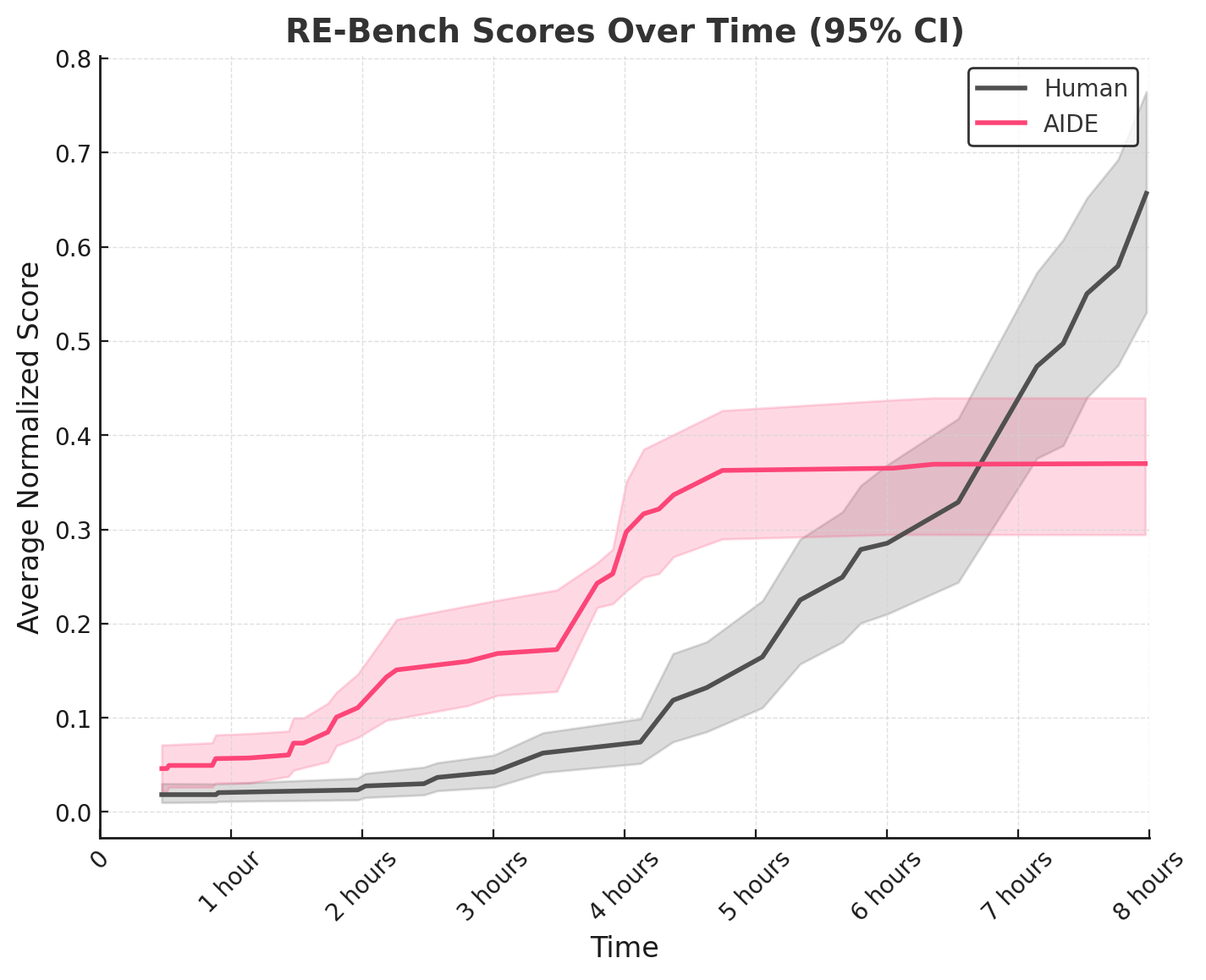
Performance over time on RE-Bench tasks compared to human experts.
Main Takeaways
- AIDE effectively trades computational resources for performance by systematically exploring the code space, achieving SOTA results on MLE-Bench.
- The tree-search approach prevents error propagation and context overflow common in linear agent workflows, enabling sustained improvement over long time windows (24 hours).
- While dominant in isolated ML tasks (Kaggle), AIDE struggles with tasks requiring broad codebase navigation or multi-step logic changes (e.g., Rust contests).
- Surpasses human experts in specialized optimization tasks like writing Triton kernels, where rapid iteration in code space offers a superhuman advantage.