📝 Paper Summary
Multi-agent systems
Self-improving agents
SiriuS optimizes multi-agent collaboration by curating a library of successful interaction trajectories and repairing failed ones via ground-truth feedback to fine-tune agent policies.
Core Problem
Optimizing multi-agent systems is difficult because credit assignment across complex interactions is ambiguous, and acquiring specialized training data for diverse agents is challenging.
Why it matters:
- Multi-agent systems often rely on fragile, manually designed prompts that do not generalize well.
- Unlike single-agent settings, it is unclear how to attribute success or failure to specific intermediate steps in a collaborative dialogue.
- Standard reinforcement learning methods struggle with the unstructured nature of language-based agent interactions.
Concrete Example:
In a physics problem, a 'Physicist' agent might correctly identify a principle, but a 'Mathematician' agent might miscalculate the formula. A standard outcome reward simply says 'fail,' making it hard for the system to learn which specific agent needs improvement.
Key Novelty
Multi-Agent Experience Replay & Augmentation
- Builds an 'experience library' by collecting successful reasoning trajectories from agent interactions, filtering by outcome reward.
- Augments failed trajectories by using a ground-truth grounded critic to guide agents in regenerating correct steps, converting failures into useful training data.
Architecture
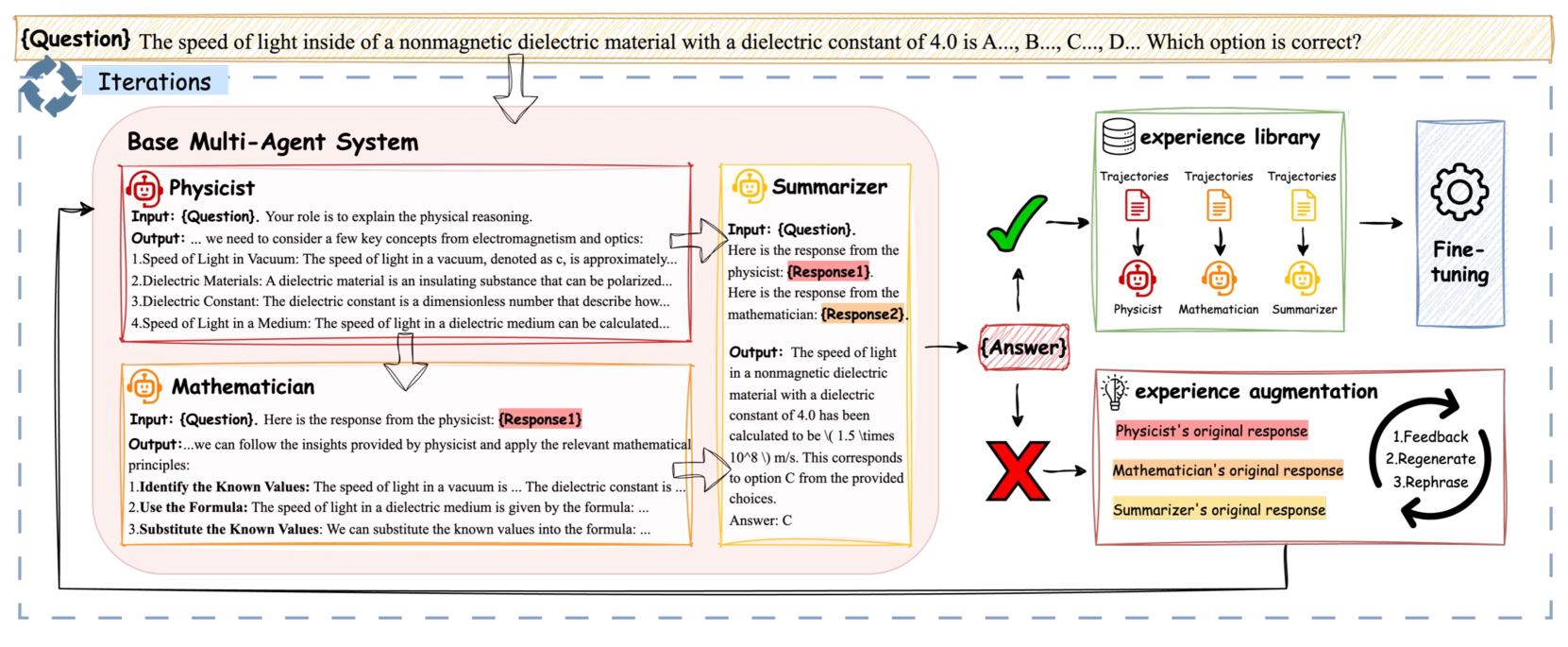
The SiriuS training pipeline: Iterative loop of action sampling, evaluation, library update, and fine-tuning.
Evaluation Highlights
- Boosts performance by 2.86% to 21.88% on reasoning and biomedical QA tasks compared to baselines.
- Enhances agent negotiation capabilities in competitive settings (Resource Exchange, Seller/Buyer scenarios).
Breakthrough Assessment
7/10
Proposes a principled, self-contained loop for multi-agent improvement without requiring dense human supervision. The reported gains (up to ~21%) are significant, though the method relies on ground-truth availability for the correction phase.