📝 Paper Summary
System Architecture for Agents
Resource Management for LLMs
AIOS is an operating system architecture that isolates LLM resources into a kernel to enable efficient scheduling, context switching, and concurrent execution for multiple LLM-based agents.
Core Problem
Current agent frameworks grant agents unrestricted access to resources (LLMs, memory, tools), leading to inefficient sequential processing, potential deadlocks, and poor utilization during concurrent execution.
Why it matters:
- Unrestricted access allows single agents to monopolize LLMs, blocking others and degrading overall system throughput.
- Existing frameworks use inefficient trial-and-error for GPU memory management, causing crashes and retries when multiple agents compete.
- Lack of standardized resource abstraction forces developers to manually handle low-level resource contention logic.
Concrete Example:
In a travel planning scenario, an agent booking flights might flood the LLM with requests. Without scheduling, a second agent trying to check calendar availability is blocked indefinitely or causes an Out-Of-Memory error, crashing both agents.
Key Novelty
LLM-based AI Agent Operating System (AIOS)
- Treats the LLM as a 'CPU core' and agent requests as 'syscalls' (e.g., llm_gen, memory_read), managed by a kernel rather than the agent directly.
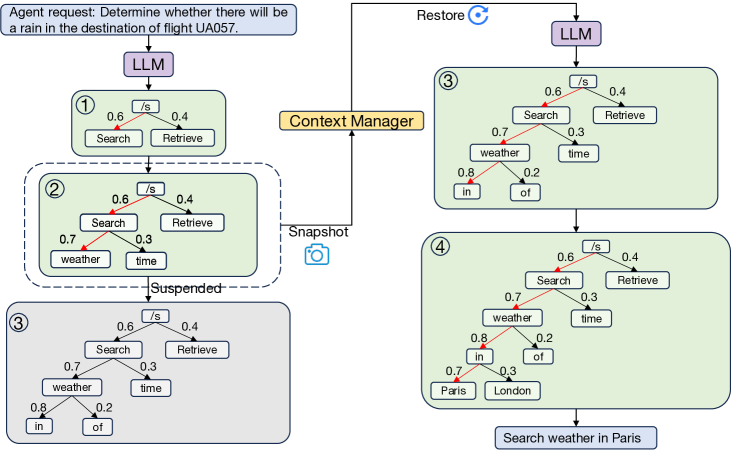
- Implements a virtual context manager that performs 'context switching' by snapshotting LLM generation states (beam search trees) to pause and resume agents.
- Uses an LRU-K eviction policy for agent memory, swapping interaction histories between RAM and disk to handle long-context overflow.
Architecture
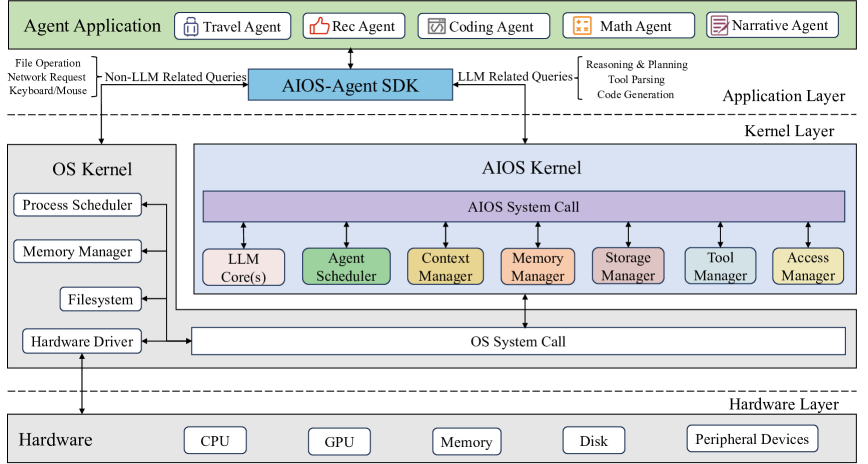
The layered architecture of AIOS, showing the separation between Application Layer (Agents/SDK), Kernel Layer (AIOS Kernel), and Hardware Layer.
Evaluation Highlights
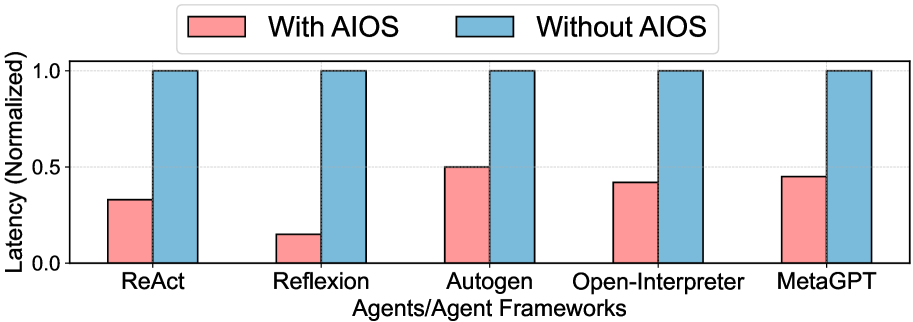
- Achieves up to 2.1x faster execution throughput (syscalls/sec) for Reflexion agents on Llama-3.1-8b compared to sequential execution.
- Maintains or improves performance on standard benchmarks (e.g., +2.3% SR on MINT with Autogen) by enforcing structural constraints via the kernel.
- Demonstrates linear scalability in execution time and waiting time when scaling from 250 to 2000 concurrent agents.
Breakthrough Assessment
8/10
Significant architectural shift treating LLMs as OS resources rather than external APIs. Effectively addresses the critical bottleneck of concurrent agent execution, though heavily reliant on local inference control.