📝 Paper Summary
Autonomous Research Agents
Information Retrieval
PaSa is a reinforcement-learning-optimized agent that autonomously searches, reads, and navigates citation networks to perform comprehensive literature surveys, significantly outperforming keyword-based search engines.
Core Problem
Standard academic search tools (e.g., Google Scholar) excel at keyword matching but fail at complex, survey-level queries that require navigating citation networks and filtering for specific methodology.
Why it matters:
- Researchers spend substantial time manually conducting literature surveys to ensure comprehensive coverage
- Keyword-based search engines often miss relevant papers that don't share exact terminology but are conceptually related (long-tail knowledge)
- Existing LLM search tools typically just rephrase queries rather than engaging in deep, multi-step research behaviors like reading papers and checking references
Concrete Example:
For the query 'Which studies have focused on non-stationary reinforcement learning using value-based methods, specifically UCB-based algorithms?', a standard search might miss papers that don't explicitly mention 'non-stationary' in the title but discuss it in the body, whereas PaSa follows citations from seed papers to find them.
Key Novelty
Dual-Agent Architecture with Session-Level RL
- Decomposes search into a 'Crawler' agent (maximizes recall via search and citation expansion) and a 'Selector' agent (maximizes precision via content reading)
- Optimizes the Crawler using a novel session-level PPO (Proximal Policy Optimization) that breaks long search trajectories into manageable segments
- Uses the Selector as an auxiliary reward model during training to solve the 'sparse reward' problem inherent in citation-based ground truth
Architecture
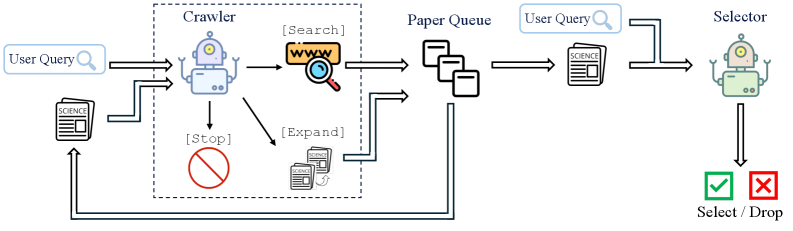
The overall workflow of PaSa, illustrating the interaction between the User, Crawler, Paper Queue, and Selector.
Evaluation Highlights
- +37.78% improvement in Recall@20 on RealScholarQuery (real-world dataset) compared to Google search enhanced with GPT-4o
- PaSa-7B outperforms PaSa-GPT-4o (the same agent architecture powered by GPT-4o prompting) by 30.36% in recall on real-world queries
- Achieves ~94% qualification rate on the synthetic training dataset AutoScholarQuery, verified by human review
Breakthrough Assessment
8/10
Strong practical contribution. Demonstrates that a 7B model trained with specialized RL significantly beats GPT-4o and Google on complex research tasks. The session-level PPO and synthetic data pipeline are highly reusable techniques.