📝 Paper Summary
Medical AI Agents
Chest X-ray Interpretation
Multimodal Medical Reasoning
MedRAX is a tool-using AI agent that orchestrates specialized medical vision models through an LLM reasoning engine to solve complex chest X-ray interpretation tasks without additional training.
Core Problem
Existing AI tools for chest X-rays (CXRs) operate in isolation (fragmented solutions) or suffer from hallucinations and poor multi-step reasoning when using general-purpose multimodal models.
Why it matters:
- Radiologists face significant time burdens analyzing CXRs, the most common diagnostic procedure (4.2 billion annually)
- End-to-end Large Multimodal Models (LMMs) lack the transparency and reliability required for high-stakes clinical decision-making
- Fragmented tools (e.g., separate classifiers and segmenters) hinder widespread clinical adoption due to lack of unified integration
Concrete Example:
When asked a complex diagnostic query requiring segmentation, measurement, and classification, a standard LMM might hallucinate findings or fail to cross-reference regions, whereas MedRAX sequentially calls a segmenter, measures the region, and then classifies it.
Key Novelty
MedRAX: A Training-Free Modular Reasoning Agent
- Integrates heterogeneous expert models (segmentation, classification, VQA) into a unified ReAct (Reasoning and Acting) loop driven by an LLM
- Decouples tool creation from agent instantiation, allowing dynamic selection of specialized tools without retraining the core reasoning engine
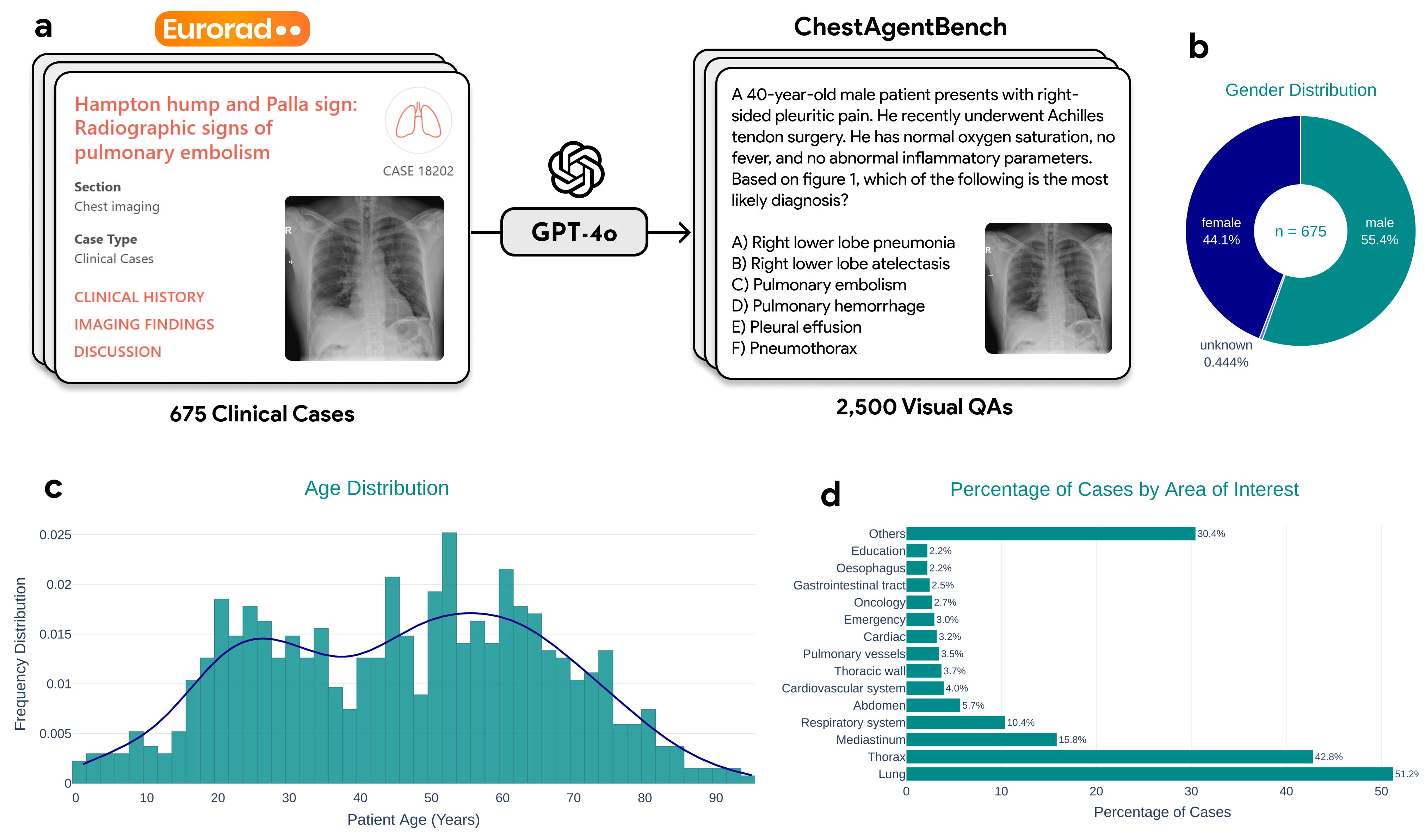
- Introduces ChestAgentBench, a large-scale benchmark derived from real clinical cases to rigorously evaluate multi-step medical reasoning
Architecture
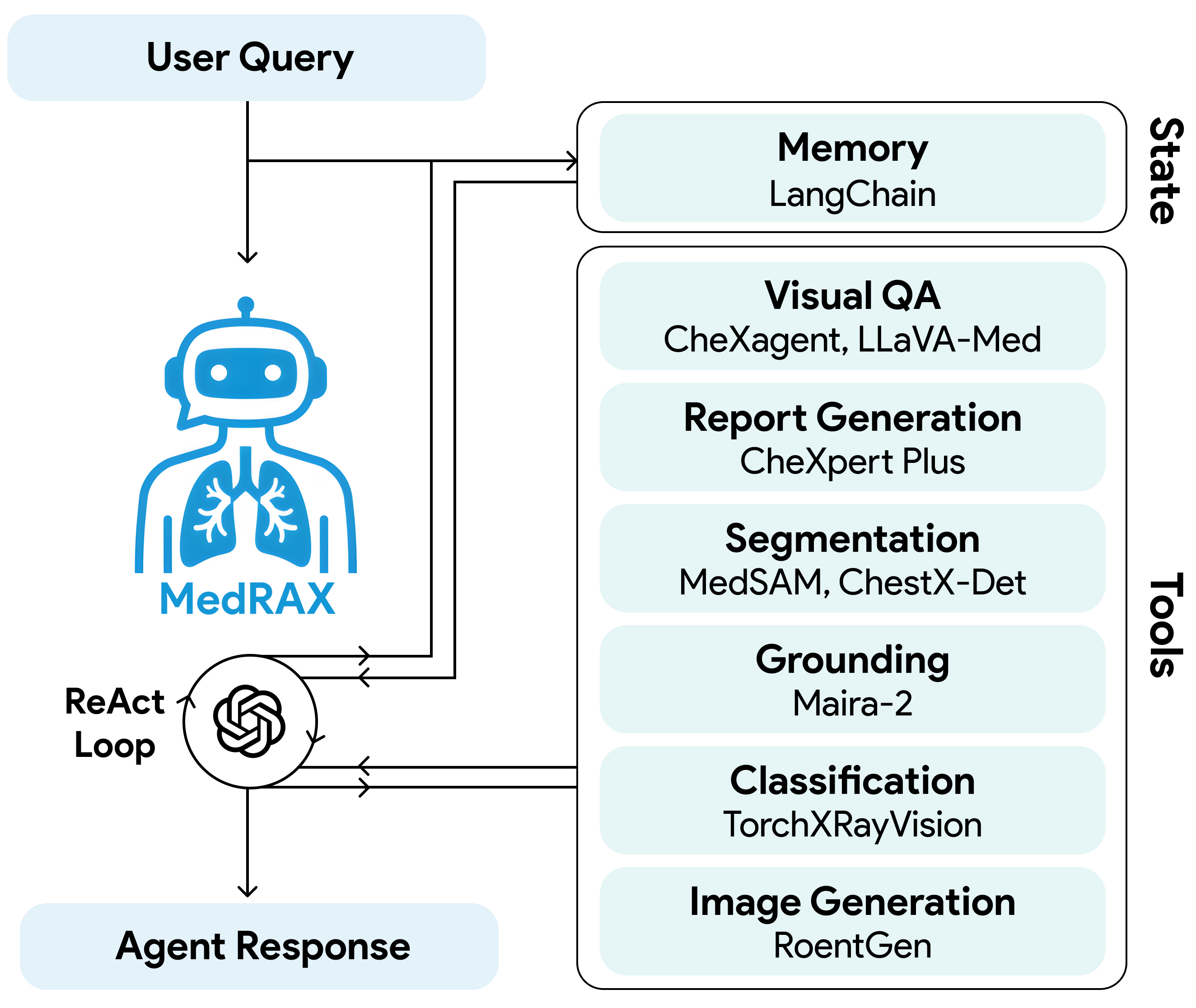
The MedRAX framework architecture showing the interaction between the LLM agent and various specialized tools.
Evaluation Highlights
- Achieves state-of-the-art performance on ChestAgentBench compared to both open-source and proprietary models
- Demonstrates substantial improvements in complex reasoning tasks (detailed finding analysis, clinical decision making) over baseline models like GPT-4o alone
- Outperforms biomedical specialist models (like LLaVA-Med and CheXagent) on the newly introduced comprehensive benchmark
Breakthrough Assessment
8/10
Significant for integrating disparate medical AI tools into a coherent agentic workflow and providing a much-needed benchmark for complex reasoning, though primarily an integration of existing SOTA tools rather than new model architecture.