📝 Paper Summary
Web Agents
Autonomous Web Navigation
LLM-based Agents
AutoWebGLM is a 6-billion parameter web agent that achieves GPT-4 level performance by using simplified HTML representations, curriculum learning on hybrid human-AI data, and self-sampling reinforcement learning.
Core Problem
Existing web agents struggle with the verbosity of real-world HTML, lack a universal action space for diverse websites, and frequently get stuck in erroneous loops without self-correction capabilities.
Why it matters:
- Standard LLMs often fail to process raw, complex HTML structures efficiently, leading to context window overflow or reasoning errors.
- Current agents lack robust self-correction mechanisms; once they make a mistake, they rarely recover, limiting practical deployment utility.
- Privacy and security constraints make collecting large-scale, high-quality human demonstration data for web navigation difficult.
Concrete Example:
When a standard agent attempts to book a flight, it might get stuck repeatedly trying to click a 'Confirm' button that is actually disabled due to a missing form field, unable to infer the dependency and rectify the error.
Key Novelty
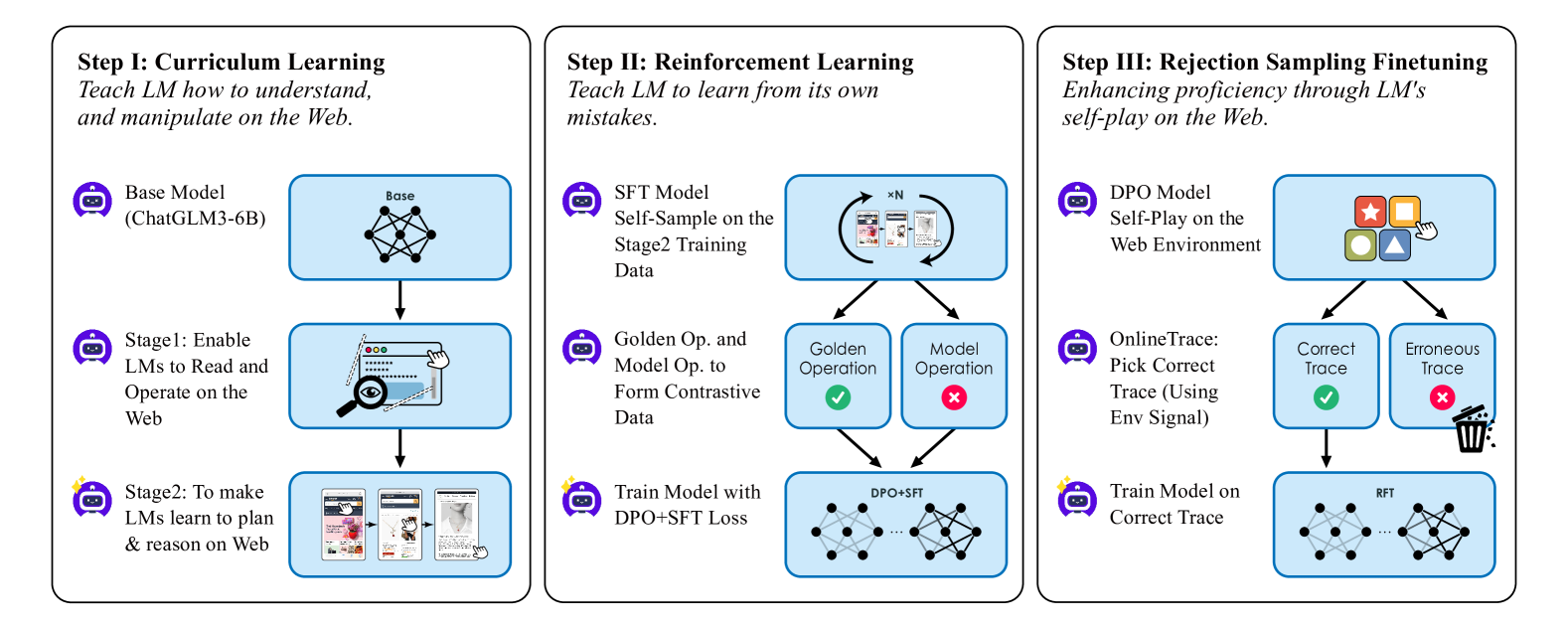
Curriculum-trained Agent with Self-Sampling Reinforcement Learning
- Simulates human browsing patterns by simplifying HTML trees to preserve only vital information, reducing token usage while maintaining structural context.
- Uses a curriculum learning strategy that progresses from simple web recognition tasks to complex multi-step workflows.
- Employs self-sampling reinforcement learning where the model generates its own negative examples (failed trajectories) to learn from mistakes, preventing recurrent errors.
Architecture
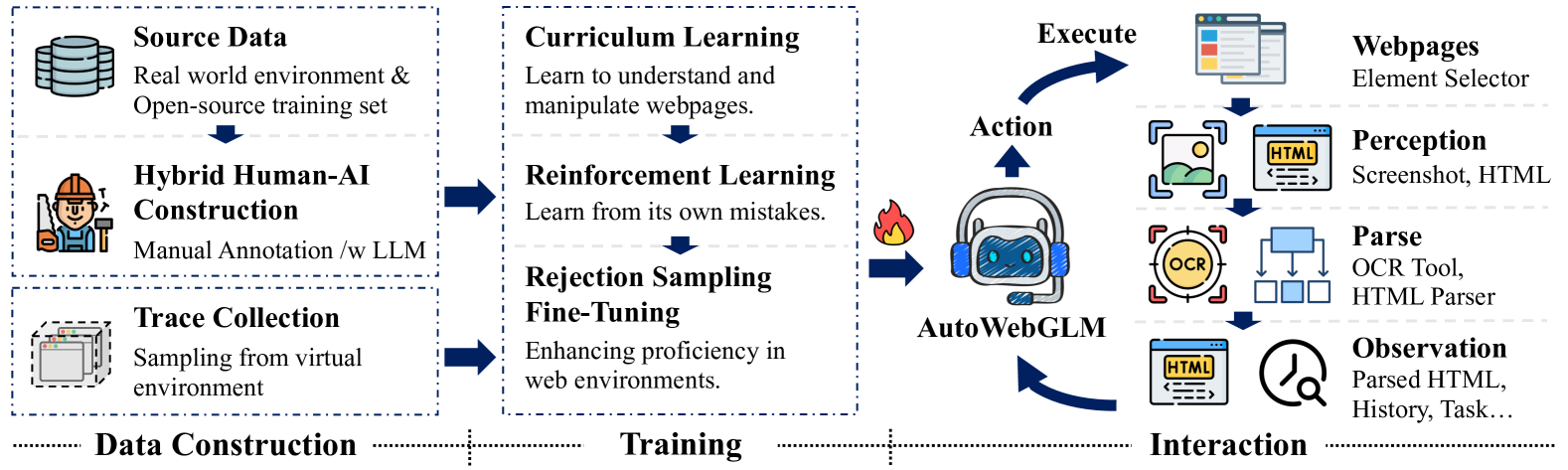
The AutoWebGLM inference framework, detailing the flow from raw webpage to action execution.
Evaluation Highlights
- Outperforms GPT-4 by approximately 20% on the Mind2Web benchmark despite having significantly fewer parameters (6B vs. >1T).
- Achieves a 15% absolute improvement in step success rate compared to the ChatGLM3-6B base model on the custom AutoWebBench.
- Maintains high success rates on cross-domain tasks, demonstrating robust generalization to unseen websites compared to baseline agents.
Breakthrough Assessment
8/10
Significant achievement in enabling a smaller (6B) model to outperform GPT-4 on web navigation through specialized data engineering and RL, lowering the barrier for deploying practical web agents.