📝 Paper Summary
Self-evolving Agentic reasoning
Simulation-based learning
Medical AI
Agent Hospital creates a virtual world where doctor agents autonomously evolve medical expertise by treating thousands of synthesized patients, achieving state-of-the-art performance on MedQA without manual labeling.
Core Problem
Medical LLMs acquire knowledge from texts (Phase 1) but lack the clinical experience gained through practice (Phase 2), and real-world trial-and-error for AI is risky and slow.
Why it matters:
- Current medical agents rely on static prompting or fine-tuning, failing to model the continuous learning process of human doctors during residency
- Annotating expert medical data for supervised learning is expensive and labor-intensive
- Directly deploying agents in real hospitals for learning purposes is ethically and practically unfeasible
Concrete Example:
A doctor agent using only base LLM knowledge might diagnose 'Herpes Zoster' incorrectly because it lacks specific case experience. In Agent Hospital, after misdiagnosing a similar patient and receiving feedback, the agent reflects, creates a rule (e.g., 'patients >50 are more susceptible'), and retrieves this experience for future accurate diagnoses.
Key Novelty
Simulacrum-based Evolutionary Agent Learning (SEAL)
- Constructs a complete hospital simulation where patients, nurses, and doctors are all agents, generating infinite interaction data without human labeling
- Enables 'MedAgent-Zero' evolution where doctor agents accumulate a 'Medical Case Base' (successes) and 'Experience Base' (reflections on failures) to improve inference at runtime, rather than updating model weights
Architecture
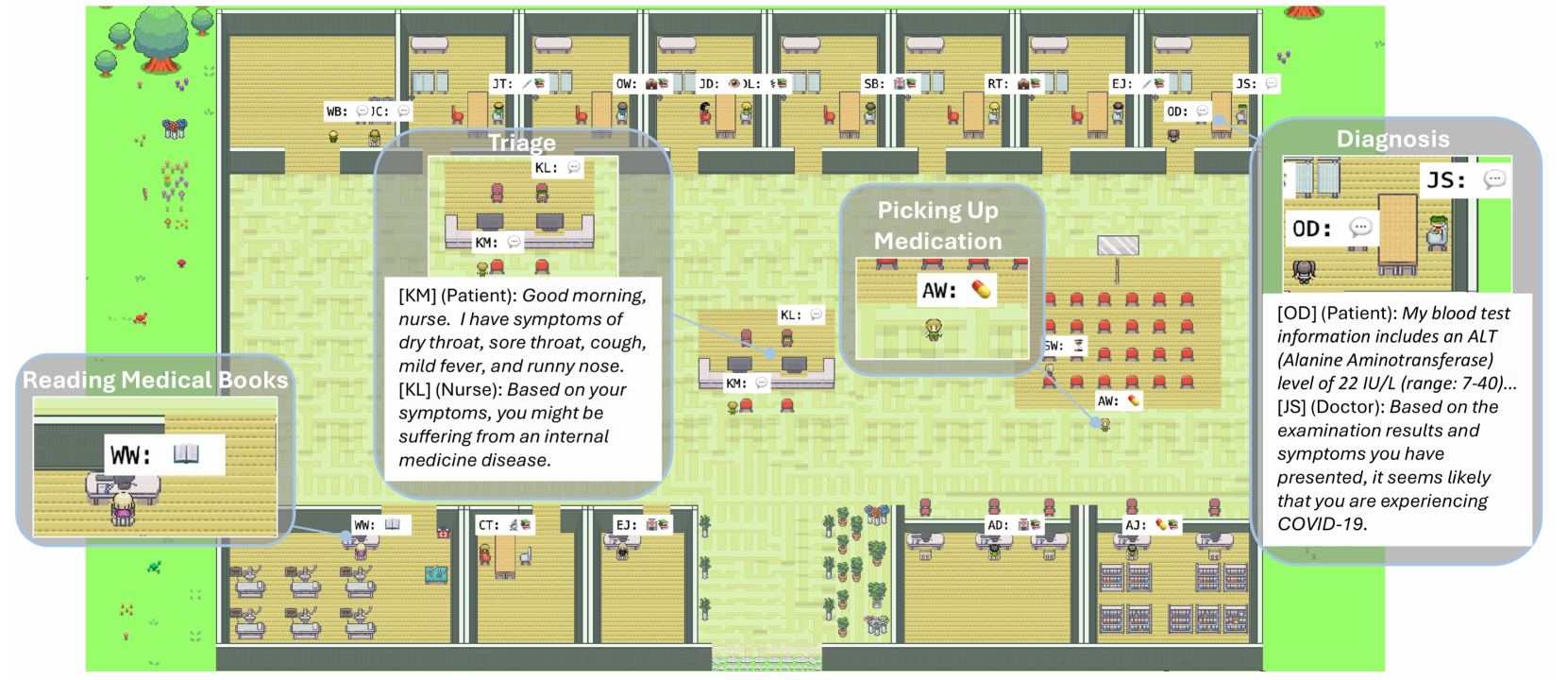
The conceptual layout of Agent Hospital, showing functional areas (Triage, Consultation, etc.) and the interactions between Patient, Nurse, and Doctor agents.
Evaluation Highlights
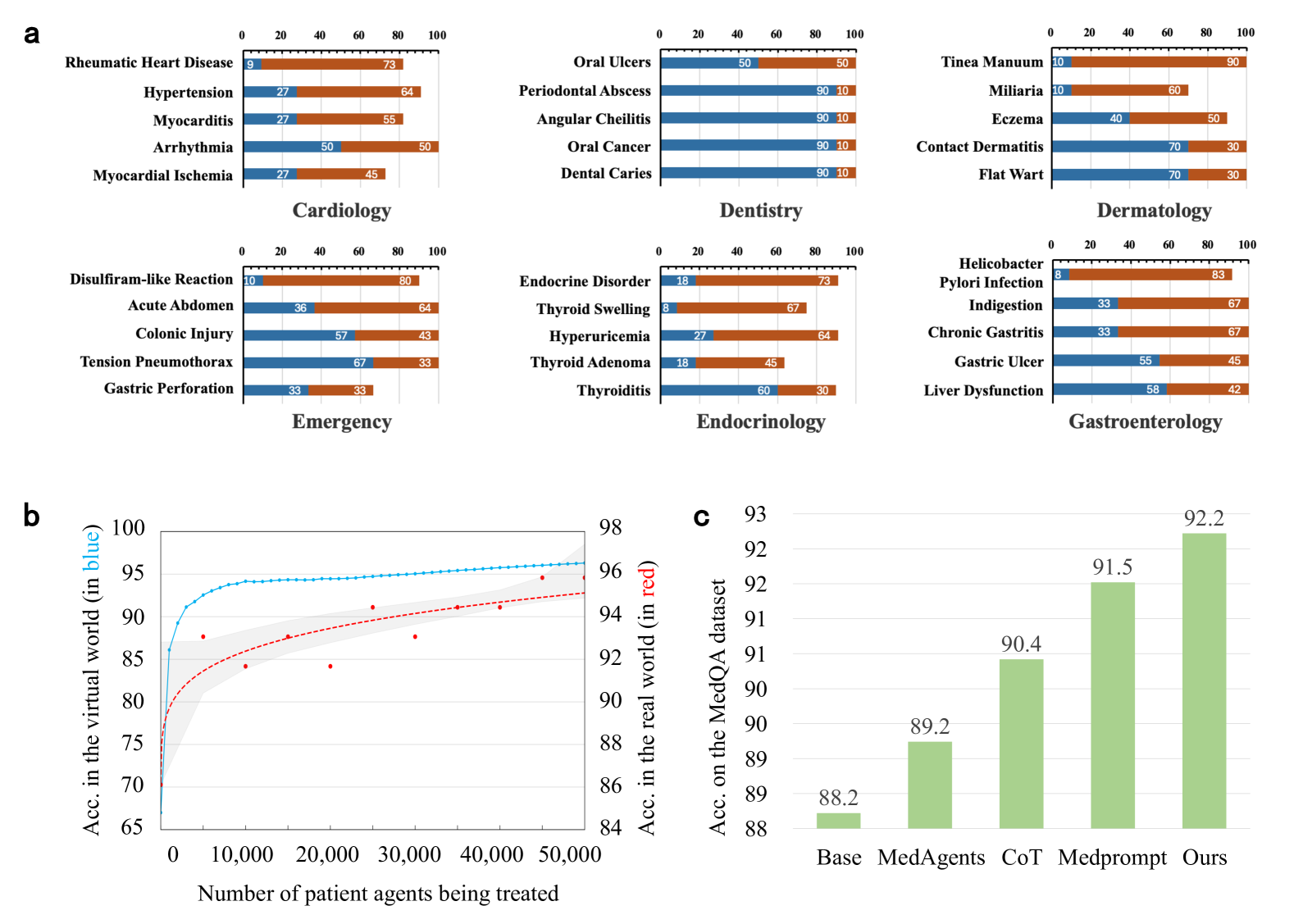
- Doctor agents improved diagnostic accuracy for Rheumatic Heart Disease from 9% (GPT-3.5 base) to 82% after evolution in the simulacrum
- Evolved agents using GPT-4o outperformed state-of-the-art baselines (MedAgents, Medprompt) on the MedQA benchmark without seeing MedQA training data
- Demonstrated scaling laws in evolution: accuracy improves logarithmically with the number of simulated patients treated (tested up to 20,000 cases)
Breakthrough Assessment
9/10
Proposes a significant paradigm shift from 'learning from data' to 'learning from simulated practice,' successfully demonstrating Sim-to-Real transfer in a complex cognitive domain (medicine) without manual supervision.