📝 Paper Summary
Conversational AI Evaluation
Synthetic Data Generation
Multi-Agent Simulation
IntellAgent automates the evaluation of conversational AI by using a policy-driven graph to generate diverse, synthetic multi-turn scenarios that test agents against complex policy constraints and tool usage.
Core Problem
Evaluating conversational agents is challenging because they must navigate complex multi-turn dialogues and strict policies, yet existing benchmarks are static, small-scale, and manually curated.
Why it matters:
- Manual benchmarks like tau-bench are expensive to scale (containing only ~50-100 samples), limiting the ability to test edge cases
- Standard evaluation metrics are often coarse-grained (pass/fail), failing to diagnose specific policy violations or tool misuse
- Real-world deployment requires high reliability in enforcing business rules (e.g., refunds, auth), which current static datasets cannot adequately stress-test
Concrete Example:
A user might request a flight modification that triggers two conflicting rules: 'cannot add insurance after booking' and 'must verify ID first.' A simple benchmark might miss whether the agent correctly prioritizes ID verification before addressing the insurance policy, whereas IntellAgent explicitly tests this interaction.
Key Novelty
Graph-based Policy Modeling for Event Generation
- Models domain policies as a graph where nodes are policies and edges represent the likelihood of co-occurrence, derived via LLM scoring
- Generates scenarios by performing random walks on this graph, allowing precise control over interaction complexity (sum of policy weights) and diversity
- Uses a symbolic entity generator to create self-consistent synthetic databases (e.g., users, reservations) that support the generated scenarios
Architecture
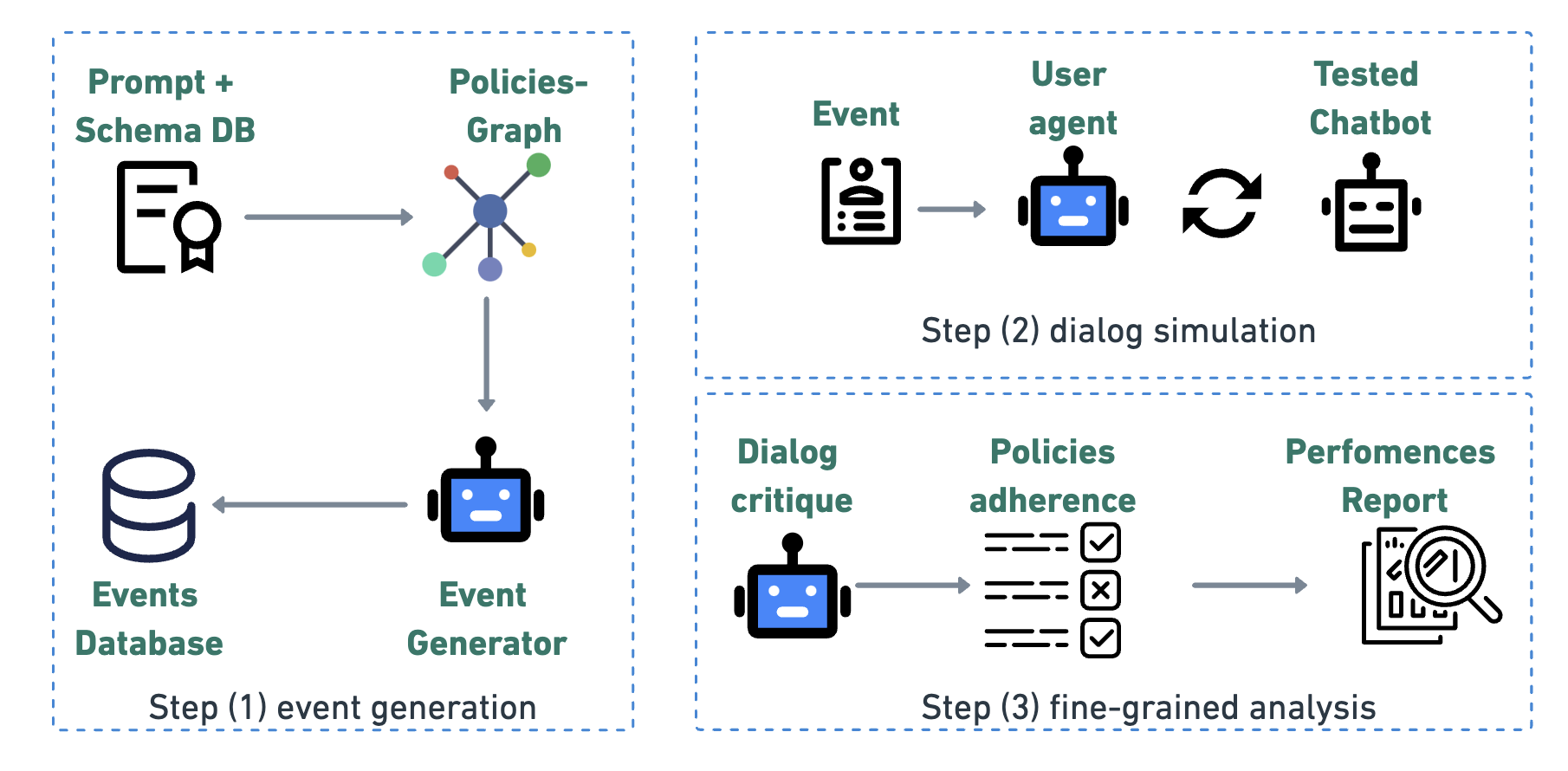
Overview of the IntellAgent pipeline from input schema to final report
Evaluation Highlights
- Strong correlation with human-curated tau-bench: Pearson coefficients of 0.98 (Airline) and 0.92 (Retail), validating the synthetic approach
- Scalability: Generated 1,000 diverse events per domain compared to tau-bench's 50 (Airline) and 115 (Retail), enabling fine-grained complexity analysis
- Identifies specific weakness: All tested models (including GPT-4o) struggle significantly with 'user consent' policies, a category not covered by existing manual benchmarks
Breakthrough Assessment
8/10
Highly practical framework that solves the data bottleneck in agent evaluation. The strong correlation with manual benchmarks suggests it can replace expensive human curation for stress-testing complex agents.