📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Efficient Inference and Training
DeepInsert improves MLLM efficiency by inserting multimodal tokens directly into intermediate LLM layers, bypassing redundant early layers without degrading performance.
Core Problem
Processing multimodal tokens alongside language prompts in early LLM layers incurs significant computational costs, despite evidence that effective cross-modal alignment naturally occurs only in deeper layers.
Why it matters:
- Hyperscaling data and parameters yields diminishing returns against training costs, creating a need for more efficient finetuning and inference.
- Multimodal inputs impose heavy computational overhead when processed fully alongside text, limiting practical viability for resource-constrained applications.
- Existing efficiency methods often rely on complex routing or token pruning, which can be fragile or architecture-specific.
Concrete Example:
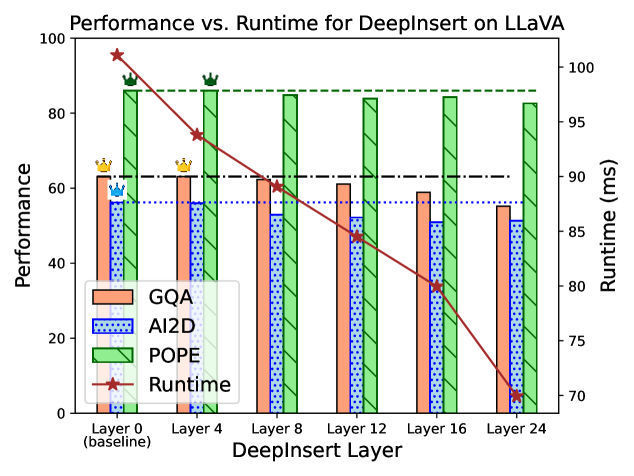
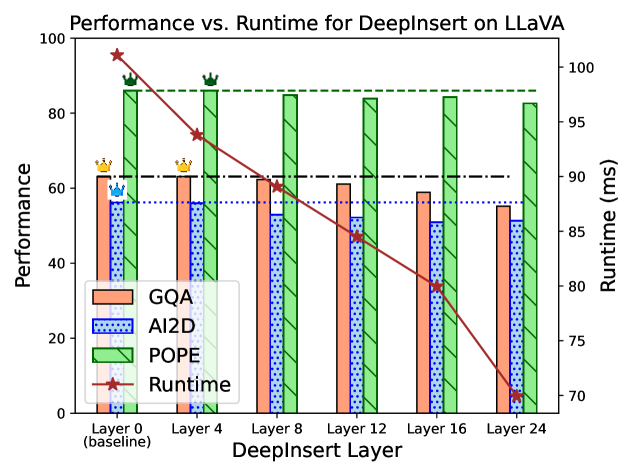
In a standard LLaVA model, 576 vision tokens are processed through all 32 layers of Llama-2-7B. DeepInsert shows that skipping the first 8 layers for these tokens (processing them only in the last 24) maintains performance while reducing multimodal FLOPs by ~25%.
Key Novelty
DeepInsert: Early Layer Bypass for MLLMs
- Identifies functional redundancy in early LLM layers for multimodal tokens via attention analysis, showing cross-modal interaction peaks in middle/late layers.
- Refactors the forward pass to split prompts: language tokens pass through all layers, while multimodal tokens are injected directly into a chosen intermediate layer.
- Achieves 'late-entry' efficiency (complementary to 'early-exit' or token pruning) by simply training the model with this bypassed architecture.
Architecture
Comparison of Standard Multimodal Processing vs. DeepInsert Framework.
Evaluation Highlights
- DeepInsert-8 (DI-8) on LLaVA-1.5-7B maintains nearly identical performance (avg drop ~1%) while skipping 25% of the multimodal compute.
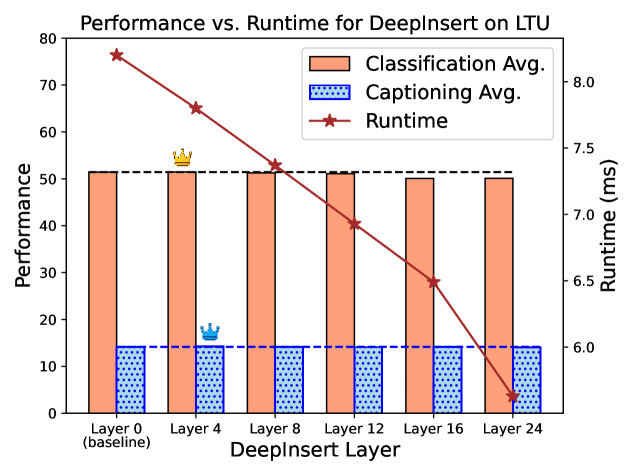
- For audio (LTU), DeepInsert-12 matches baseline performance while using only 50% of the layers for audio tokens.
- For molecular data (MolCA), DeepInsert-12 matches or outperforms the baseline despite skipping the first 12 layers (50% reduction).
Breakthrough Assessment
7/10
Simple, effective, and broadly applicable method for efficiency. While conceptually straightforward, the empirical validation across diverse modalities (vision, audio, molecules) and the preservation of performance make it a strong practical contribution.