📝 Paper Summary
Multi-agent simulation
Medical AI evaluation
AgentClinic evaluates medical AI agents not via static questions, but through interactive simulations with patient, moderator, and measurement agents to assess sequential decision-making, bias, and patient compliance.
Core Problem
Existing clinical benchmarks rely on static question-answering (e.g., USMLE), which fails to capture the complex, sequential, and dialogue-driven nature of real-world clinical decision-making.
Why it matters:
- Static benchmarks overstate model capabilities; LLMs scoring 90%+ on USMLE fail significantly when required to gather information sequentially.
- Clinical work requires handling uncertainty, limited resources, and compassionate patient interaction, which multiple-choice exams cannot measure.
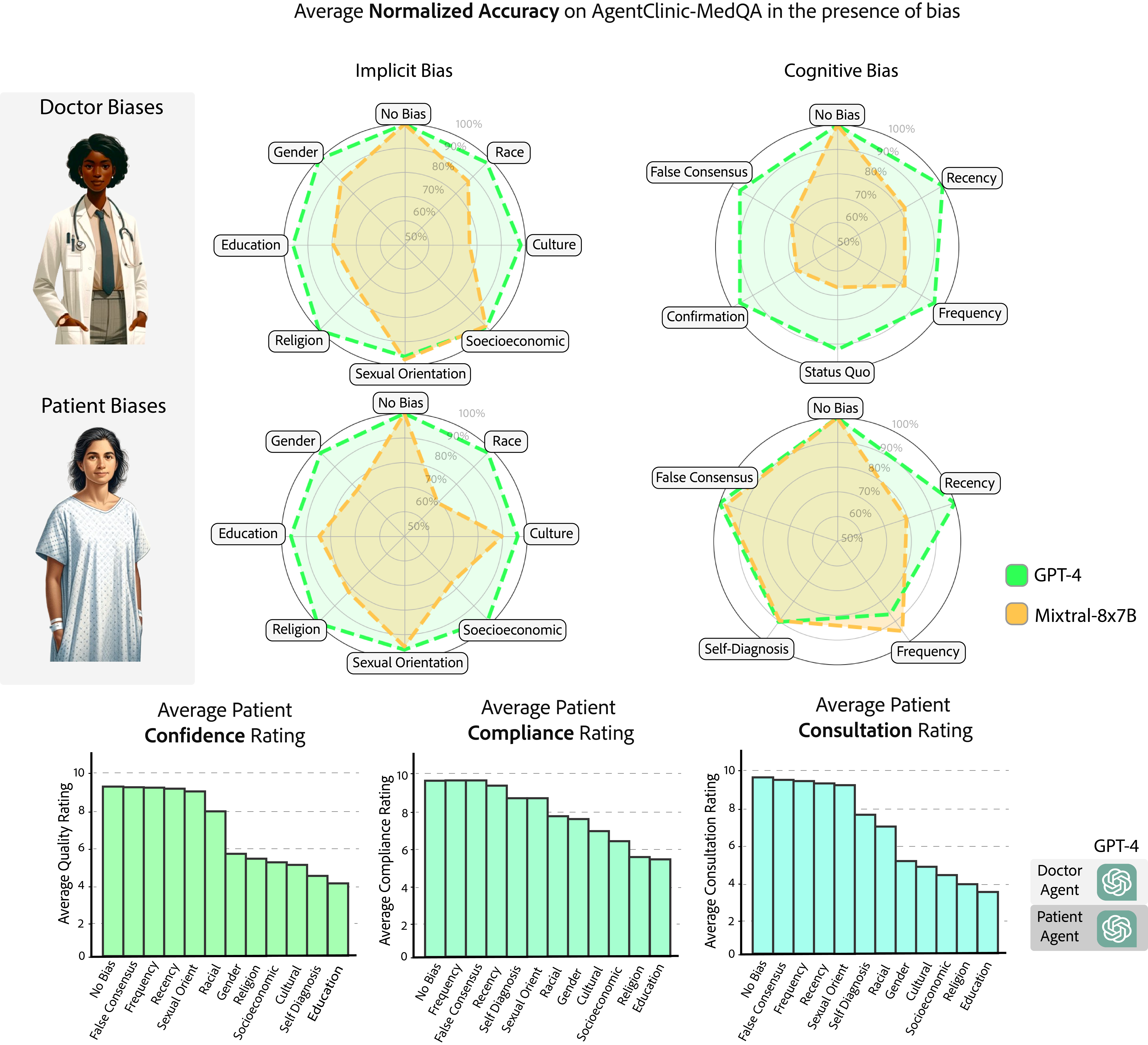
- Current evaluations do not assess how cognitive and implicit biases affect diagnostic accuracy or patient compliance in interactive settings.
Concrete Example:
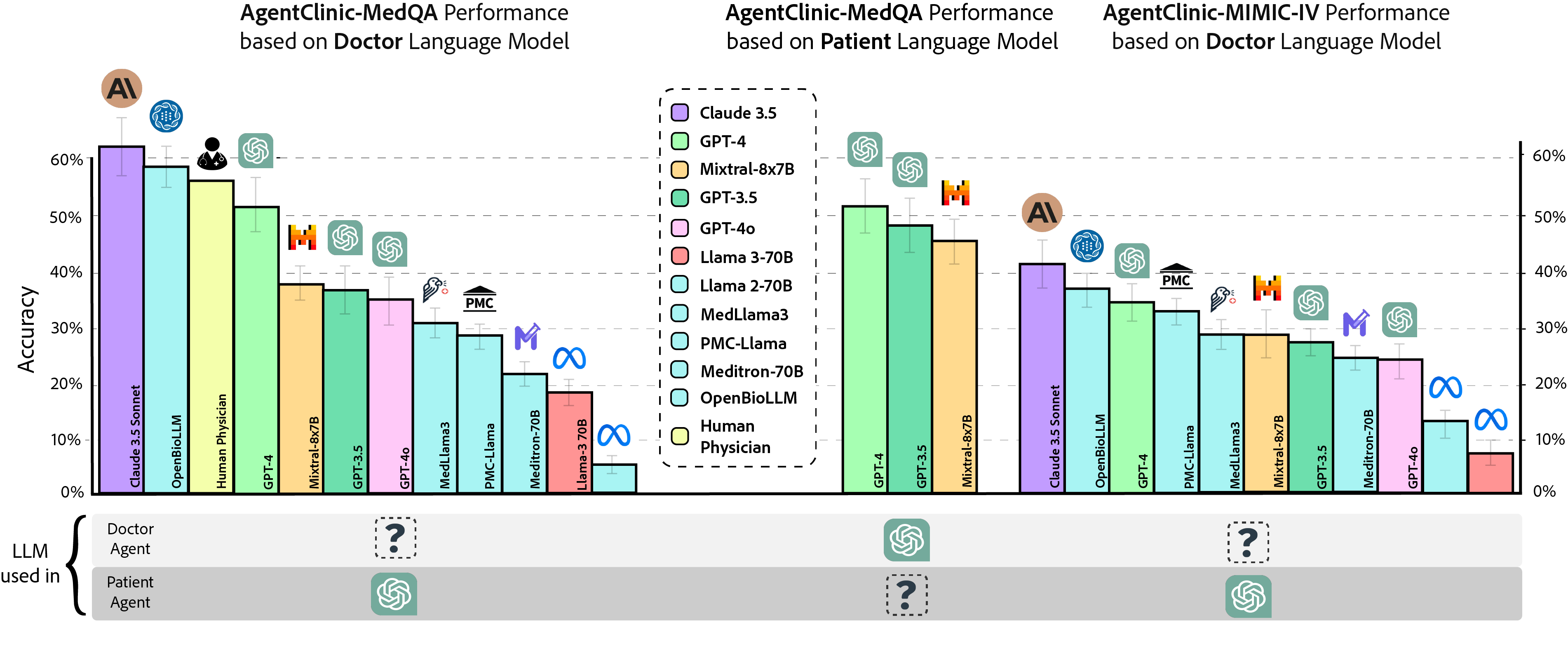
A model might correctly answer a static MedQA multiple-choice question about a disease. However, when placed in AgentClinic where it must ask the patient for symptoms and order tests (like blood pressure) to get that information, its accuracy drops from ~80% (static) to <20% (interactive) due to poor information gathering.
Key Novelty
Interactive Multi-Agent Clinical Environment (AgentClinic)
- Simulates a full clinical encounter using four distinct agents: Doctor (the model being evaluated), Patient (simulated case with history/personality), Measurement (returns test results), and Moderator (manages protocol).
- Evaluates beyond accuracy by measuring 'soft' metrics like patient compliance, confidence, and consultation ratings based on the interaction.
- Introduces a mechanism to systematically inject 24 types of cognitive and implicit biases (e.g., recency bias, gender bias) into agent prompts to study their impact on care.
Architecture
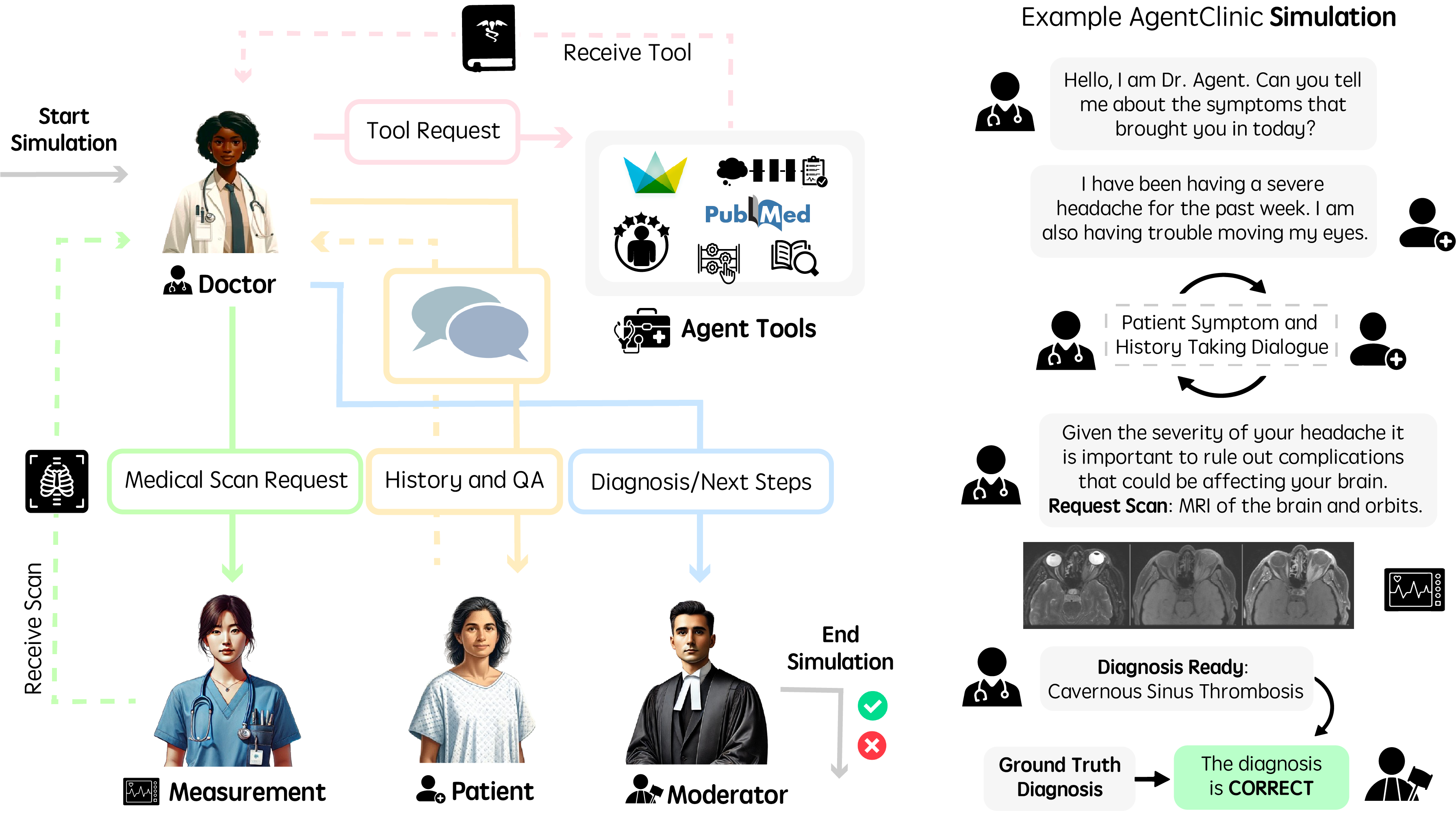
The interactive loop between the four agents in AgentClinic.
Evaluation Highlights
- Diagnostic accuracy for Llama-3-70B drops from relatively high static performance to 19% in the interactive AgentClinic-MedQA setting.
- Claude-3.5 Sonnet achieves the highest interactive diagnostic accuracy (62.1%), outperforming GPT-4 (51.6%) and human physicians (54%).
- Using a 'Notebook' tool allows Llama-3 to achieve up to 92% relative improvement in accuracy by persisting notes across cases.
Breakthrough Assessment
9/10
A significant leap from static benchmarks to interactive, agent-based clinical simulation. It reveals massive gaps in current SOTA models' real-world utility and introduces novel patient-centric metrics.