📝 Paper Summary
RL-based Agent Training
Agent Frameworks
Agent Lightning decouples agent execution from training by formulating agent runs as Markov Decision Processes, enabling RL optimization of any agent architecture with minimal code changes.
Core Problem
Existing RL frameworks for LLMs are coupled with specific agent implementations or limited to static single-turn tasks, making it difficult to train complex, diverse, or dynamic agents.
Why it matters:
- Real-world agents (e.g., coding, tools) generate rich interaction data that far surpasses human-curated datasets in scale and diversity
- Prompt engineering alone cannot reliably solve complex tasks like end-to-end software development or private-domain workflows
- Current methods struggle with dynamic execution flows where the number of turns or tool calls varies based on runtime context
Concrete Example:
A RAG agent might dynamically decide whether to refine a query or answer directly. Current RL frameworks struggle to model this variable-length interaction without explicit, custom parsing of the execution graph for every new agent type.
Key Novelty
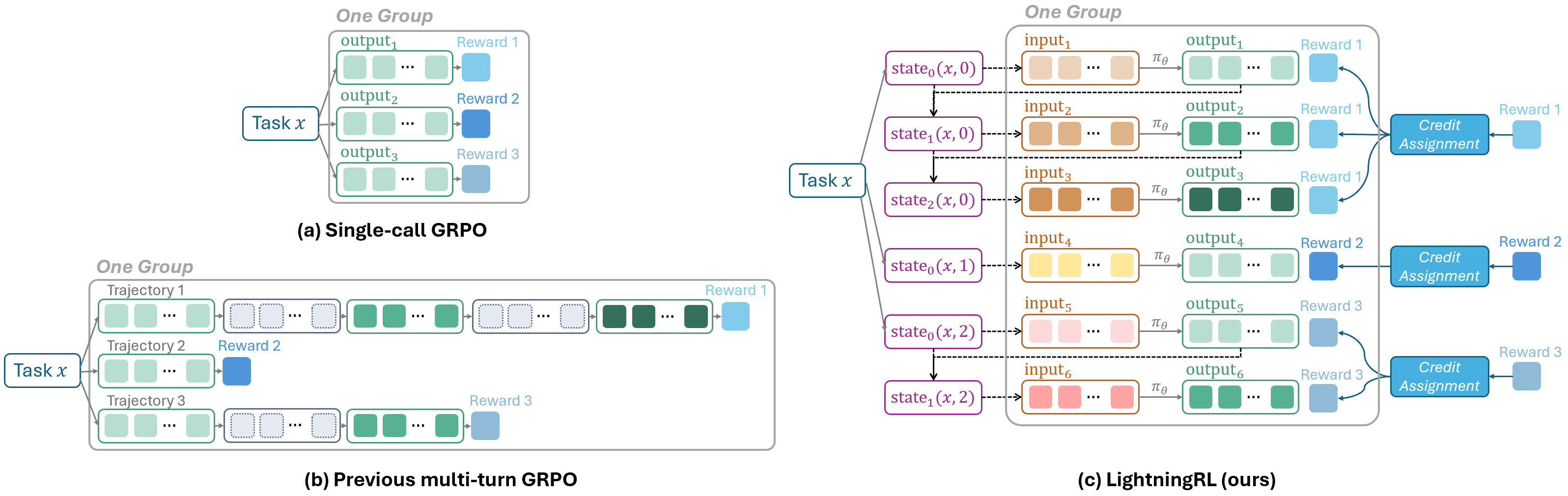
Training-Agent Disaggregation Architecture
- Treats agent execution as a black-box software run, capturing snapshots of 'semantic variables' (inputs/outputs) to form a standard Markov Decision Process (MDP)
- Uses a 'Lightning Client' sidecar to transparently collect execution traces and a 'Lightning Server' to handle RL updates, separating the training logic from the agent's code
- Introduces 'Automatic Intermediate Rewarding' (AIR) to assign credits to intermediate steps (like successful tool calls) based on system signals, mitigating sparse rewards
Architecture
The Training-Agent Disaggregation architecture showing the separation between the Agent Environment (Lightning Client) and the Training Service (Lightning Server).
Evaluation Highlights
- Consistent performance gains across three diverse agent types: Text-to-SQL (LangChain), RAG (OpenAI Agents SDK), and Math Tool-Use (AutoGen)
- Text-to-SQL agent achieves steady reward improvement from ~0.2 to ~0.7 over 400 training steps
- Math agents using tools show stable convergence, proving the framework handles tool-use logic effectively
Breakthrough Assessment
8/10
Significant engineering contribution by decoupling training from execution. Enables 'train any agent' capability, which is a major blocker for scaling RL beyond simple chat models.