📝 Paper Summary
Vehicular Metaverses
AI Agent Migration
Network Security
This paper secures the migration of AI agents between roadside units in vehicular metaverses by using multi-agent reinforcement learning to defend against DDoS attacks and a trust mechanism to filter malicious infrastructure.
Core Problem
Migrating AI agents between RoadSide Units (RSUs) is vulnerable to DDoS attacks that saturate bandwidth and malicious RSUs that steal data or provide false information.
Why it matters:
- Vehicular metaverses require real-time, immersive services (like AR navigation) which fail if migration is delayed by attacks.
- Existing defenses often focus on traditional vehicular networks or simplified attack models, lacking comprehensive strategies for the dynamic, resource-intensive nature of metaverse agent migration.
- Compromised infrastructure can mislead autonomous vehicles, posing safety risks beyond just service interruption.
Concrete Example:
A vehicle moving between coverage zones needs to migrate its AI assistant to the next RSU. A DDoS attack floods the RSU with traffic, causing a timeout. Simultaneously, a compromised RSU accepts the migration but steals the user's location history.
Key Novelty
Secure AI Agent Migration Framework with MAPPO and Trust Assessment
- Models the defense against traffic-based attacks (DDoS) as a Partially Observable Markov Decision Process (POMDP) solved by Multi-Agent Proximal Policy Optimization (MAPPO), allowing RSUs to cooperatively learn optimal pre-migration strategies under attack.
- Integrates a trust assessment mechanism that calculates a 'malicious score' for RSUs based on anomaly detection, dynamically prohibiting interaction with compromised infrastructure.
Architecture
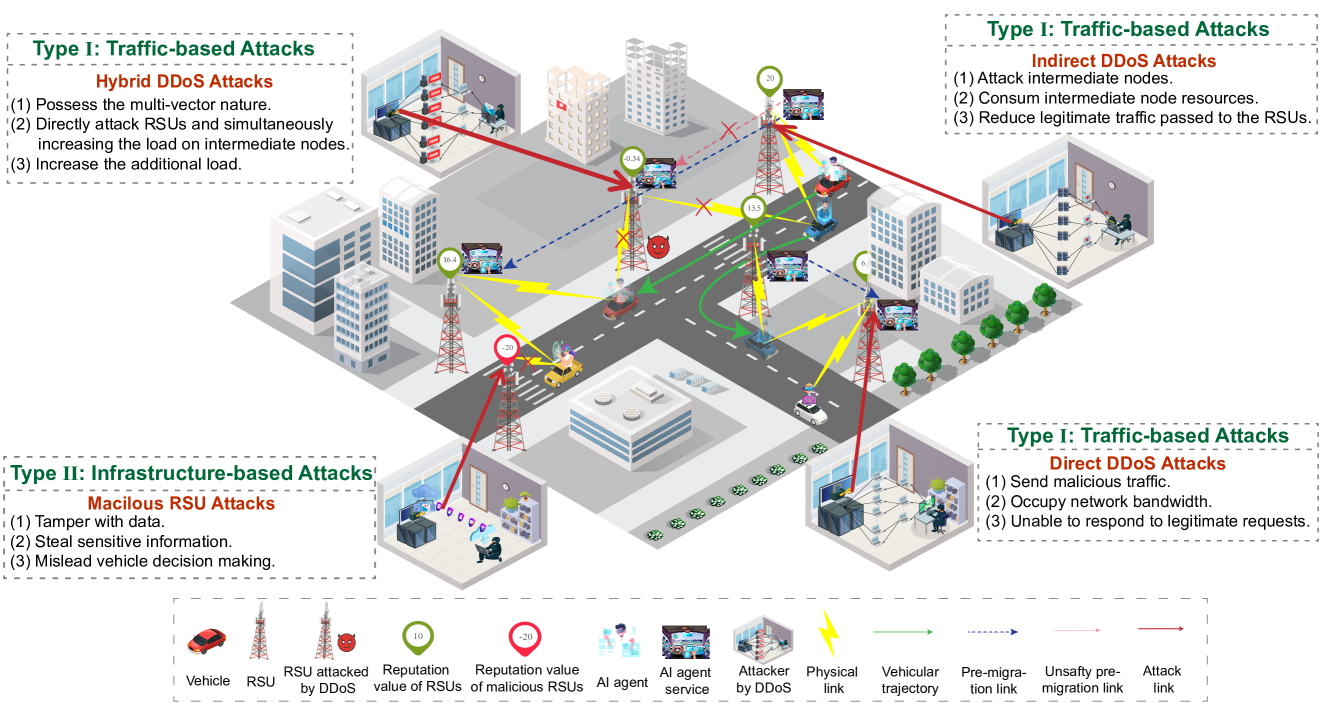
Illustration of the system model including Traffic-based attacks (DDoS) and Infrastructure-based attacks (Malicious RSUs) in a vehicular metaverse.
Evaluation Highlights
- Reduces the total latency of AI agent migration by approximately 43.3% compared to baselines.
- The proposed MAPPO (Multi-Agent Proximal Policy Optimization) algorithm achieves higher rewards and lower latency convergence compared to MADDPG and single-agent PPO.
Breakthrough Assessment
4/10
Applies established MARL techniques (MAPPO) to a specific niche (Vehicular Metaverses). While effective, it is an application of existing methods to a new domain rather than a fundamental algorithmic breakthrough.