📝 Paper Summary
Agentic RAG pipeline
Graph-based RAG pipeline
KGARevion is a biomedical agent that prompts an LLM to generate knowledge triplets, then verifies and corrects them using a fine-tuned model grounded in structural knowledge graph embeddings before answering.
Core Problem
General-purpose LLMs lack specialized biomedical knowledge and often hallucinate, while standard RAG methods relying on direct KG retrieval miss implicit relationships and lack mechanisms to verify retrieved information.
Why it matters:
- Incorrect medical advice from AI can have serious safety implications in clinical settings
- Standard retrieval fails to capture biological similarities between proteins that lack direct edges in a Knowledge Graph
- Current systems struggle to integrate codified scientific knowledge (databases) with tacit clinical intuition (LLM reasoning)
Concrete Example:
When asking about gene interactions with the Heat Shock Protein 70 family involved in Retinitis Pigmentosa 59, an LLM might hallucinate a connection or fail to distinguish between HSPA4 and HSPA8 due to subtle semantic overlap, whereas KGARevion explicitly verifies these links against the KG structure.
Key Novelty
Agentic Generate-Verify-Revise Loop with Structural KG Embeddings
- Instead of just retrieving from a graph, the agent first hallucinates (generates) potential triplets using the LLM's intuition
- It then strictly verifies these generated triplets using a separate LLM fine-tuned with TransE structural embeddings from the Knowledge Graph to catch errors
- If errors are found, a 'Revise' action corrects the triplets before the final answer is generated, ensuring grounding
Architecture
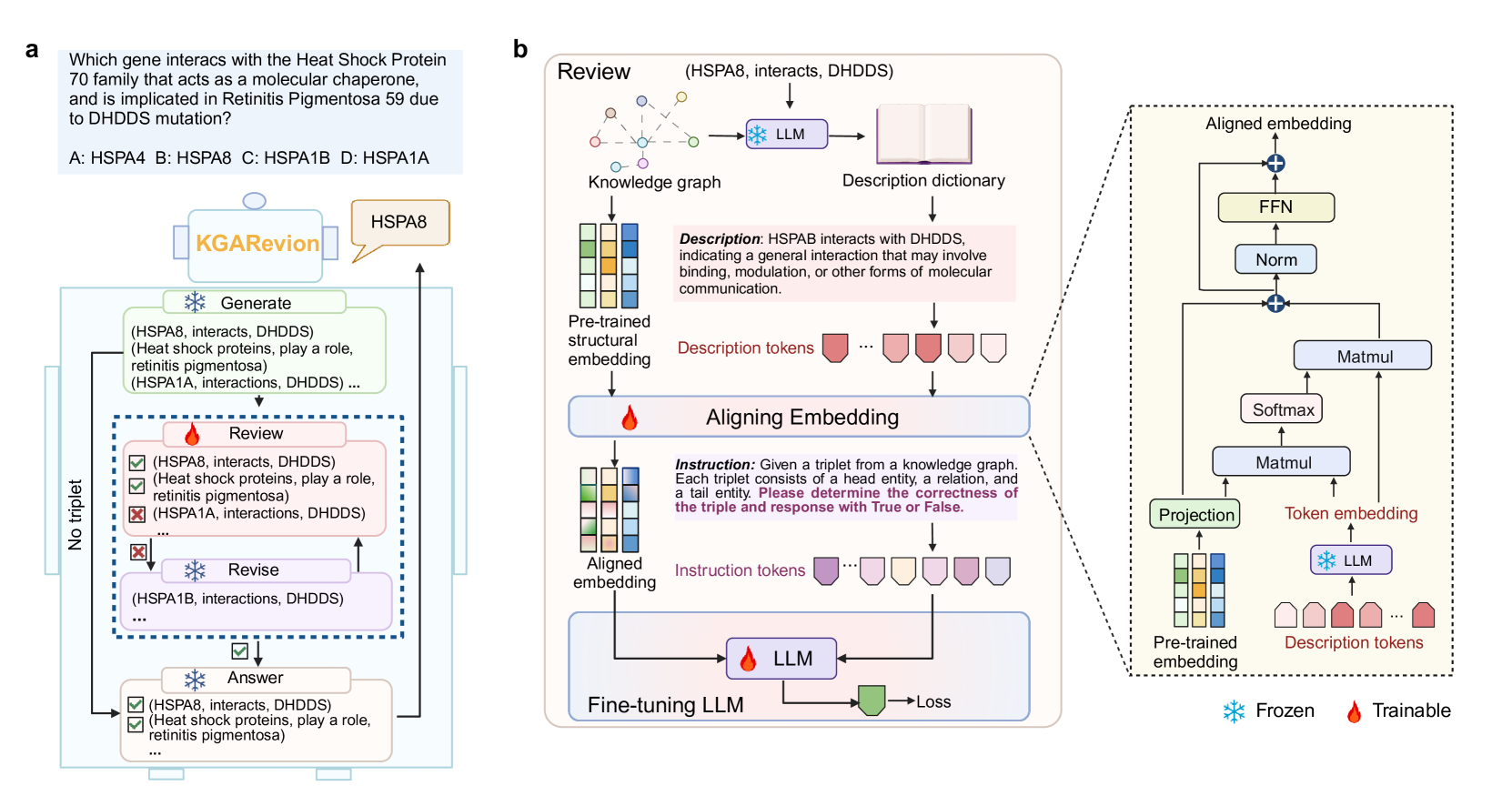
The KGARevion framework illustrating the four-step process: Generate, Review, Revise, and Answer.
Evaluation Highlights
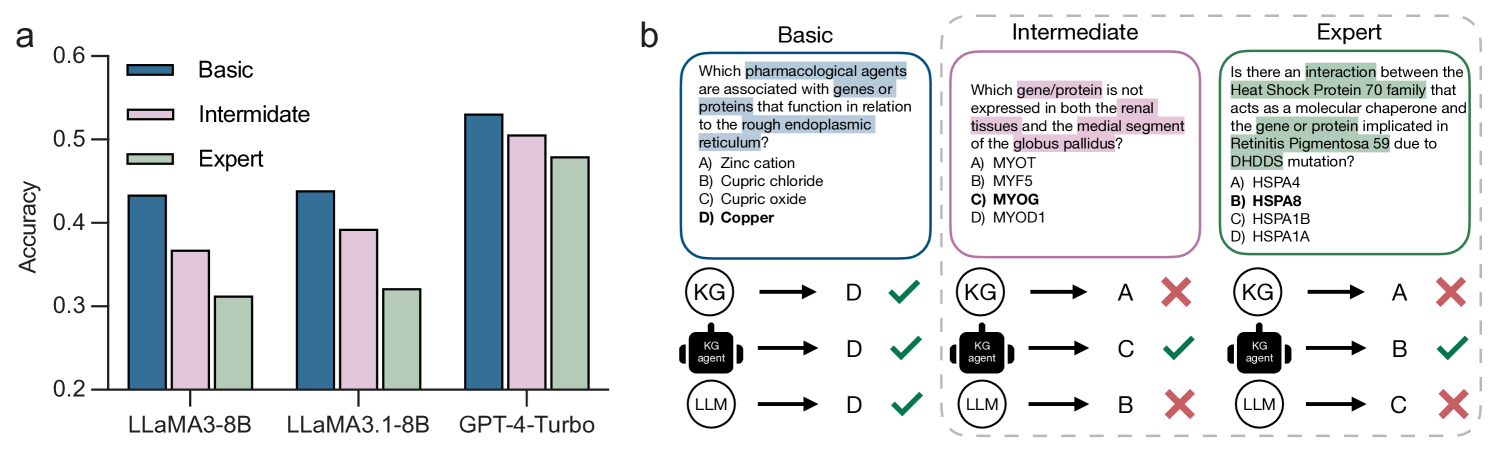
- Achieves a 6.75% accuracy improvement over 15 baseline models across seven medical QA datasets
- Improves accuracy by 10.4% on three newly curated medical QA datasets designed with varying levels of semantic complexity
- Demonstrates strong zero-shot generalization on AfriMed-QA (African healthcare dataset), effectively handling underrepresented medical contexts
Breakthrough Assessment
8/10
Strong methodological contribution by combining generative flexibility with strict structural verification. Significant empirical gains on specialized benchmarks and good robustness analysis.