📊 Experiments & Results
Evaluation Setup
Reranking top-100 documents retrieved by first-stage retriever
Benchmarks:
- BEIR (Diverse retrieval tasks (Climate-FEVER, DBPedia, etc.))
- TREC Deep Learning (DL19-23) (Passage ranking)
Metrics:
- nDCG@10
- Latency (ms/query)
- Statistical methodology: Paired Student’s t-test with p<=0.01 with Bonferroni correction
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Generalization across diverse datasets (BEIR/MS MARCO) shows FirstMistral often outperforming the original FIRST implementation. | ||||
| FiQA (BEIR) | nDCG@10 | 0.4223 | 0.4778 | +0.0555 |
| TREC-COVID (BEIR) | nDCG@10 | 0.7913 | 0.7666 | -0.0247 |
| Evaluation on out-of-domain TREC DL datasets confirms FIRST effectiveness is competitive with full-generation models. | ||||
| TREC DL19-23 (Average) | nDCG@10 | 0.7166 | 0.7209 | +0.0043 |
| Latency experiments quantify the efficiency gains of single-token decoding. | ||||
| TREC DL20 | Latency (s/query) | 3.06 | 1.79 | -1.27 |
| TREC DL20 | Output Tokens | 711 | 18 | -693 |
Experiment Figures
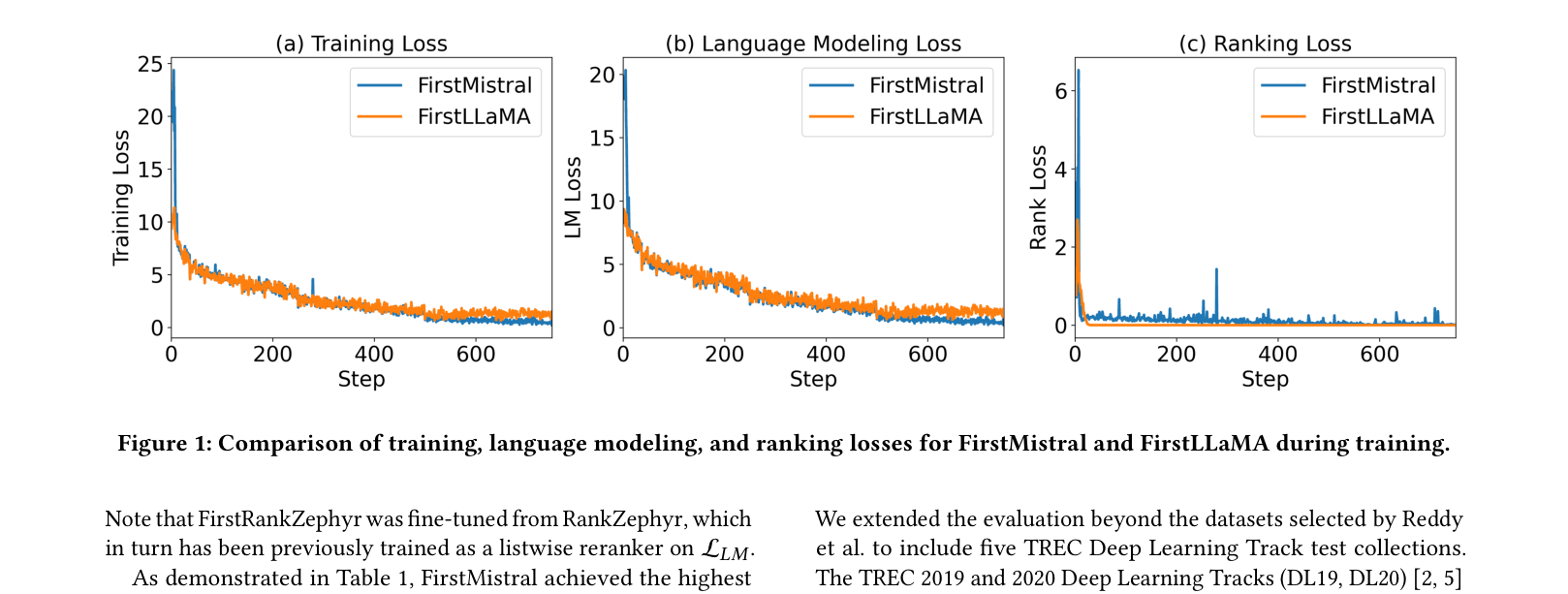
Training loss curves for FirstMistral vs FirstLLaMA
Main Takeaways
- FIRST generalizes well to Mistral-v0.3 (FirstMistral), often outperforming the original Zephyr-based implementation
- Models trained solely on L_LM (RankZephyr/RankVicuna) show strong zero-shot ability to perform single-token reranking, validating that L_LM implicitly learns ranking signals
- Counter-intuitively, fine-tuning an already ranking-tuned model (RankZephyr) on the FIRST objective performs worse than fine-tuning from the base model (Zephyr), suggesting interference between objectives
- Efficiency gains (~40% latency reduction) are consistent across datasets and backbones
- Retriever quality impacts FIRST similarly to traditional rerankers: better retrieval helps, but with diminishing returns