📝 Paper Summary
Knowledge Internalization
Language Modeling Objectives
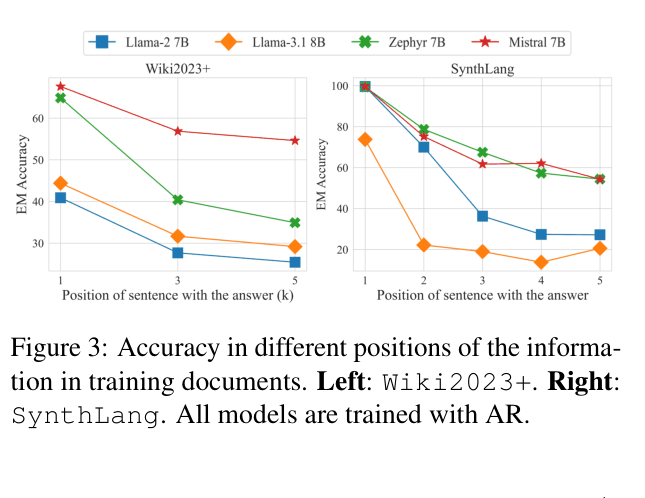
Language models struggle to answer questions about facts located in the middle or end of training documents due to auto-regressive training, but adding noise or shuffling sentences mitigates this issue.
Core Problem
Despite minimizing perplexity during training, language models suffer from 'perplexity curse' and positional bias: they fail to extract factual knowledge described in the middle or end of training documents via question-answering.
Why it matters:
- Standard auto-regressive training creates excessive reliance on previous tokens, meaning facts are only memorable given their specific preceding context
- This prevents models from answering flexible user queries that don't match the exact training document sequence
- Models may appear to 'know' a document based on low perplexity while being unable to actually recall the information when prompted
Concrete Example:
If a training document lists film facts in order (1. Genre, 2. Star, 3. Producer, 4. Release Date), an AR-trained model can answer questions about the Genre (1st sentence) but fails to answer 'When was it released?' (4th sentence), even though it saw the data many times.
Key Novelty
Positional Bias in Parametric Knowledge & Denoising Auto-Regressive Mitigation
- Identifies that LMs have a specific 'positional bias' in *storage*: facts appearing later in a training document are harder to retrieve via prompts than facts at the beginning
- Attributes this to auto-regressive training, where models learn to predict tokens based on specific long contexts rather than the facts themselves
- Proposes using simple regularization—specifically Denoising Auto-Regressive training (replacing tokens with random noise)—to break dependencies on previous tokens and improve recall
Architecture
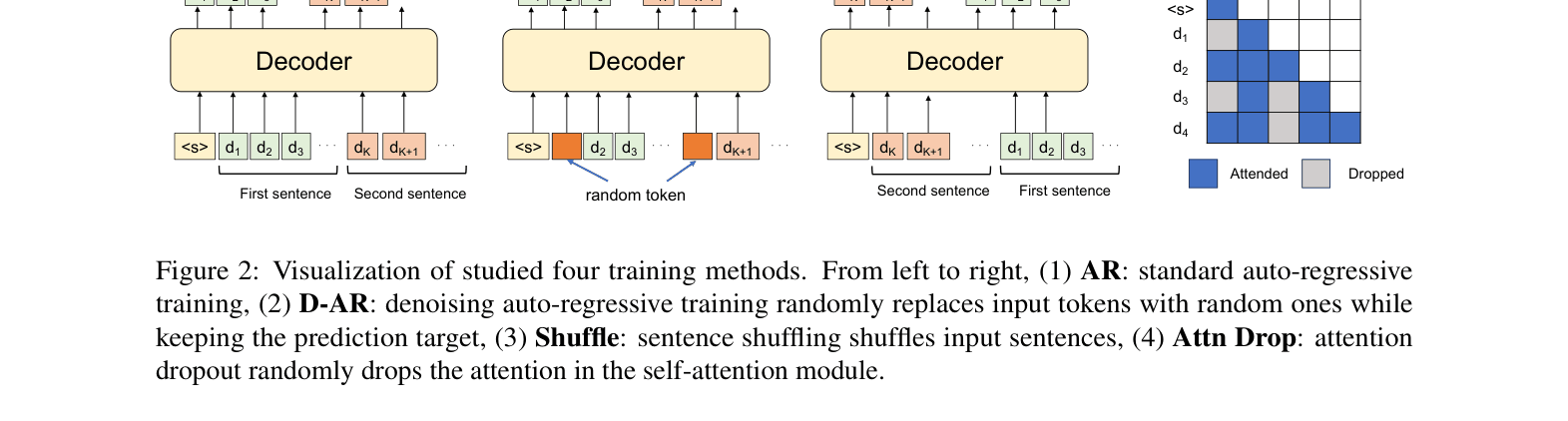
Visualization of four training methods: Standard Auto-regressive (AR), Denoising AR (D-AR), Sentence Shuffling, and Attention Dropout.
Evaluation Highlights
- Llama-2-7B's recall accuracy drops from ~41% (1st sentence) to ~15% (6th sentence) on Wiki2023+ when trained with standard auto-regressive loss
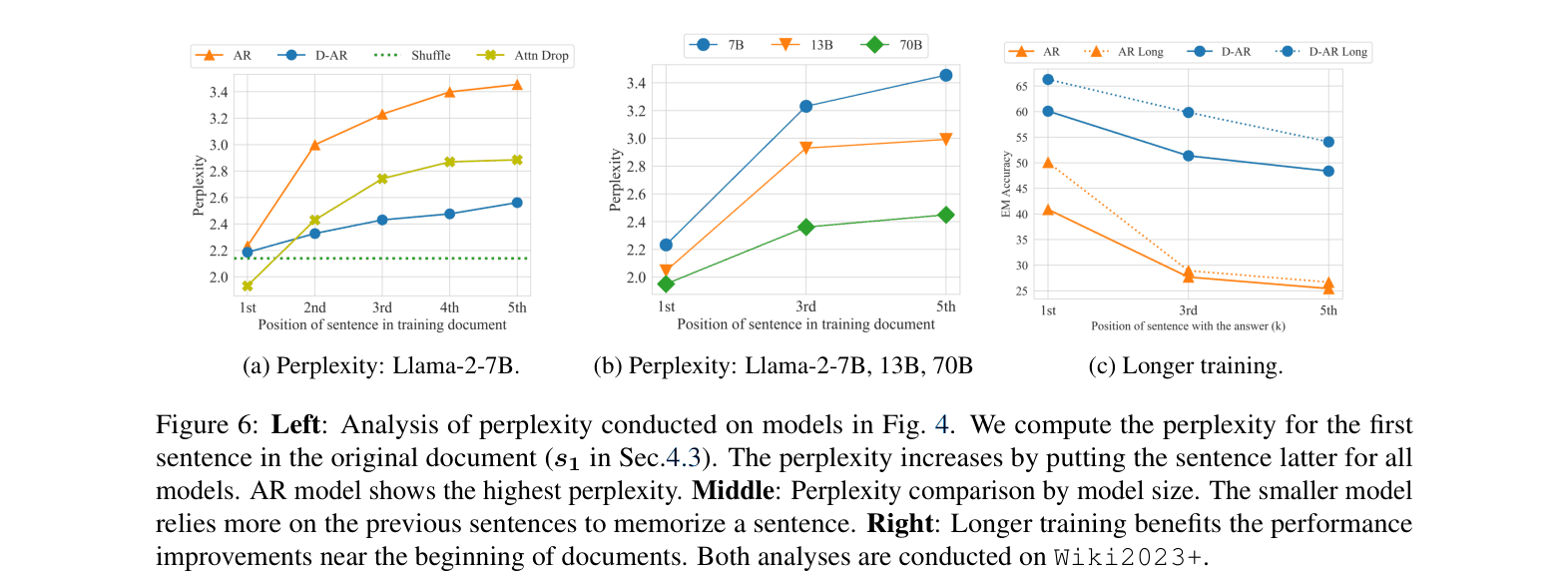
- Denoising Auto-Regressive (D-AR) training improves Llama-2-7B's recall significantly, raising 1st-position accuracy to 60.1% and maintaining >20% accuracy in later positions
- Large models are not immune: Llama-2 70B trained with AR shows a steep performance drop after the first sentence, while D-AR keeps degradation to <2%
Breakthrough Assessment
7/10
Highlights a fundamental flaw in how LMs store knowledge from training data (positional bias in storage) and offers a simple, effective fix. Strong empirical evidence, though the solution (denoising) is a known technique applied to a new problem.