📝 Paper Summary
Multi-call tool use with fixed plan
Tool-use post-training
Agentic data synthesis
xLAM is a family of open-source Large Action Models optimized for agent tasks via a unified data pipeline that synthesizes verifiable function-calling data and standardizes diverse agent trajectories.
Core Problem
Open-source agent models lag behind proprietary ones because existing agent datasets are scarce, heterogeneous in format, and often contain low-quality or hallucinated actions.
Why it matters:
- Proprietary models (like GPT-4) dominate agent tasks, limiting accessibility and transparency for the open-source community
- Existing open-source datasets suffer from format inconsistency, making it difficult to unify data or transfer knowledge across different agent environments
- Data quality issues, such as invalid function calls and hallucinations, severely hamper the reliability of smaller open-source models in practical applications
Concrete Example:
In function calling, a model might hallucinate an argument not present in the user query (e.g., inventing a date) or generate a function name that doesn't exist in the provided tool list. Existing datasets often lack the execution-based verification needed to catch these errors before training.
Key Novelty
Unified Data Pipeline & APIGen Synthesis for Action Models
- Standardizes diverse agent datasets into a single unified format (task instruction, tools, few-shot, query, steps) to facilitate effective multi-task training
- Employs APIGen, a synthesis framework that generates verifiable function-calling data by executing APIs to filter out hallucinations and invalid arguments
- Releases a family of models (1B to 8x22B) specialized for actions, including 'tiny' models (1B) that outperform much larger general-purpose models on function calling
Architecture
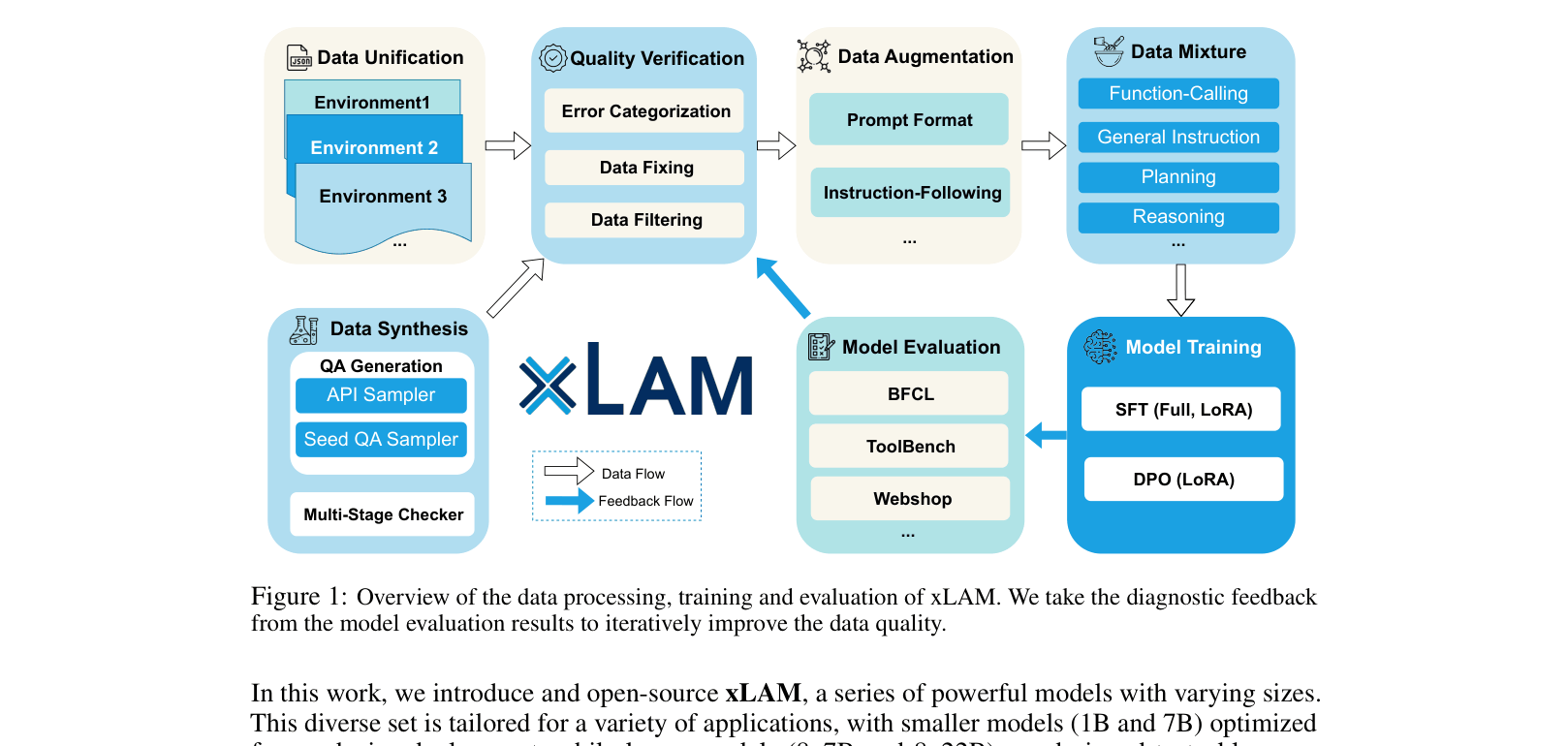
The complete data processing, training, and evaluation pipeline for xLAM
Evaluation Highlights
- xLAM-8x22b-r achieves #1 rank on Berkeley Function-Calling Leaderboard (87.31% accuracy), outperforming GPT-4-0125-Preview (85.79%)
- xLAM-1b-fc-r (1B params) achieves 75.43% on Berkeley Function-Calling Leaderboard, surpassing GPT-3.5-Turbo (75.41%) and Claude-3-Haiku
- xLAM-7b-r achieves highest Success Rate (0.414) on Webshop, outperforming GPT-4-0125-preview (0.375) and AgentOhana-8x7b (0.331)
Breakthrough Assessment
8/10
Strong contribution to open-source agent capabilities. The 1B model's performance on function calling is particularly impressive, proving the value of their data synthesis pipeline. Top-1 ranking on BFCL validates the approach.
