📝 Paper Summary
Multi-call tool use with flexible plan
Agentic RAG pipeline
TxAgent is a fine-tuned LLM agent that personalizes therapeutic decisions by iteratively retrieving knowledge from 211 verified biomedical tools and generating transparent reasoning traces.
Core Problem
General-purpose LLMs lack real-time access to updated biomedical knowledge, hallucinate medical facts, and struggle with multi-step reasoning required for personalized treatment plans.
Why it matters:
- Retraining LLMs for new drugs (like those approved in 2024) is computationally expensive and suffers from catastrophic forgetting
- Precision medicine requires integrating diverse factors (genetics, comorbidities, drug interactions) that single-step RAG cannot handle effectively
- Existing tool-use models fail to manage large tool spaces (hundreds of tools) and often cannot recover from failed initial tool calls
Concrete Example:
When asked for the dosage of 'Kisunla' (approved in 2024, post-training cutoff), a standard LLM hallucinates or pleads ignorance. TxAgent recognizes the knowledge gap, calls 'get_dosage', retrieves FDA records, and synthesizes a correct answer.
Key Novelty
TxAgent: Full-stack agent optimization for therapeutic reasoning
- Combines a specialized retrieval module (ToolRAG) to dynamically select from 211 tools with a fine-tuned reasoning agent that generates step-by-step plans
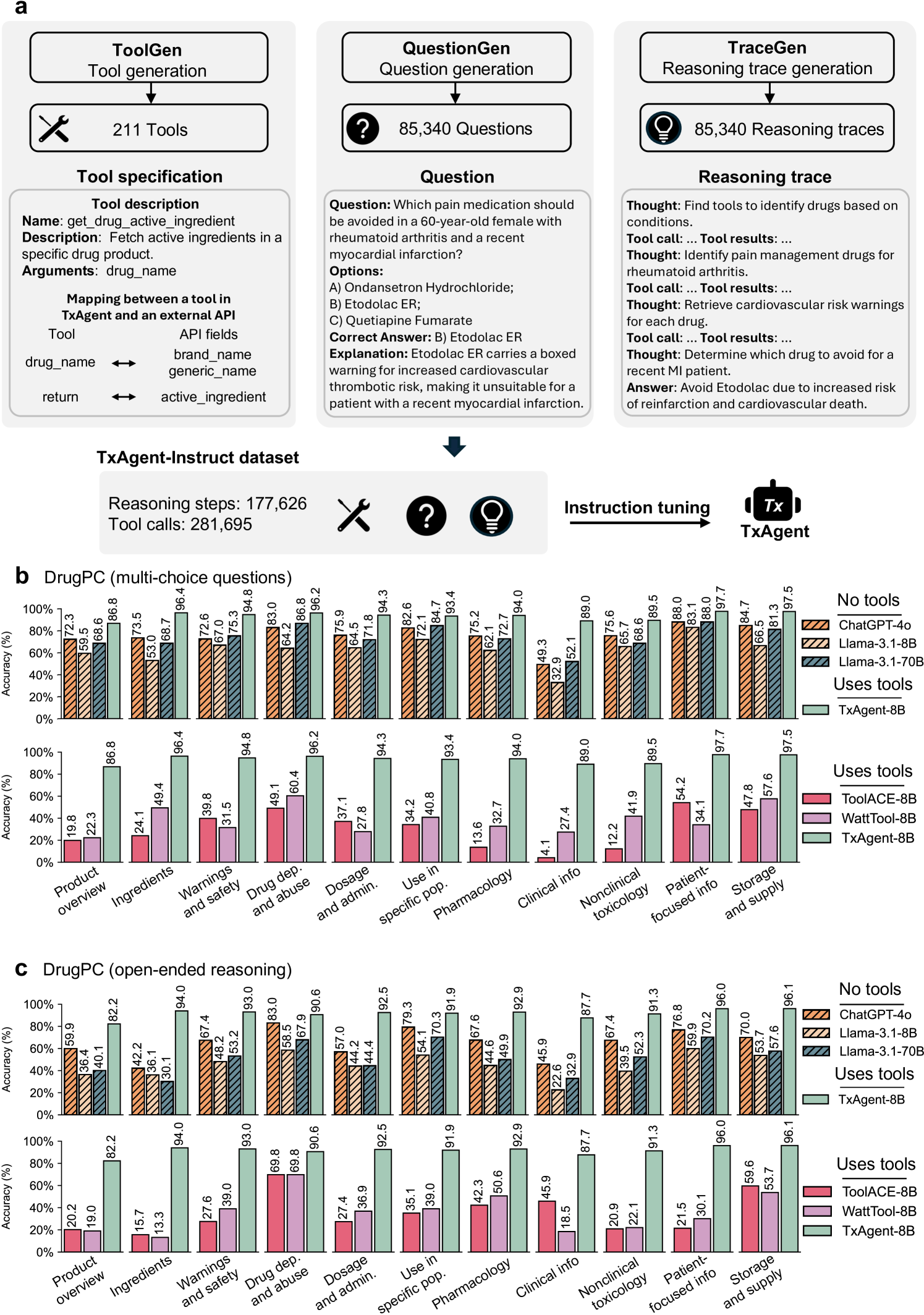
- Uses a multi-agent data synthesis pipeline (QuestionGen, TraceGen) to create a massive instruction-tuning dataset (378k samples) derived from FDA labels and knowledge graphs
Architecture

Overview of the TxAgent framework including the ToolUniverse, ToolRAG retrieval, and the iterative reasoning loop.
Evaluation Highlights
- 92.1% accuracy on open-ended DrugPC reasoning tasks, outperforming GPT-4o by 25.8% and Llama-3.1-70B-Instruct by 39.3%
- Achieves variance of <0.01 when testing across brand names, generic names, and descriptions, compared to GPT-4o's variance of 9.96
- Outperforms DeepSeek-R1 (671B) by 7.5% on the open-ended TreatmentPC personalized medicine benchmark despite being a 8B parameter model
Breakthrough Assessment
8/10
Significant advance in domain-specific agentic reasoning. Effectively solves the 'too many tools' problem via retrieval and demonstrates superior generalization across drug terminologies compared to frontier models.