📝 Paper Summary
Agentic Reinforcement Learning (ARL)
Post-training optimization
Tool-use and Reasoning integration
The paper empirically proves that joint training of reasoning and tool-use in agents creates conflicting gradient updates, and proposes DART to disentangle these capabilities via separate LoRA modules.
Core Problem
Most Agentic RL methods jointly optimize reasoning and tool-use on shared parameters, assuming they are compatible, but this actually causes performance degradation due to interference.
Why it matters:
- Improving tool-use often degrades reasoning (and vice versa) in a 'seesaw' phenomenon, limiting overall agent performance.
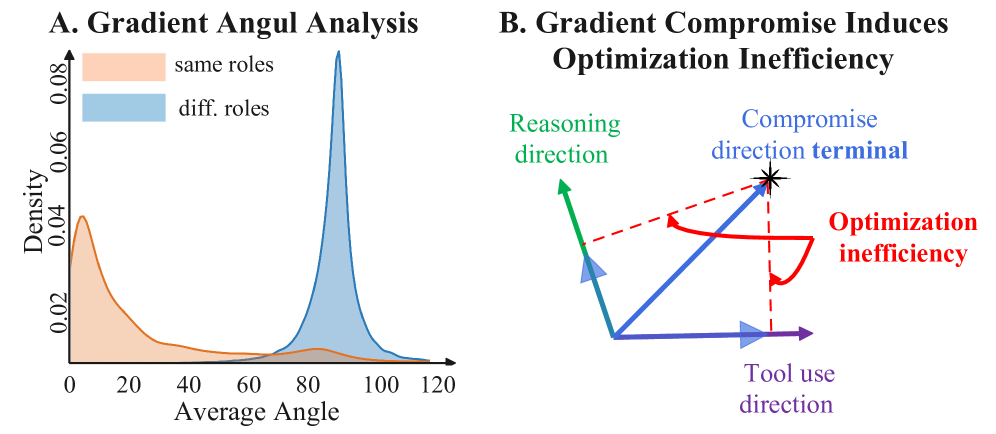
- Orthogonal gradient directions between reasoning and tool tokens cause the shared model to update in a 'compromise' direction that is suboptimal for both.
- Current paradigms rely on implicit assumptions of compatibility that have not been rigorously tested until now.
Concrete Example:
When an agent attempts to solve a complex question requiring both logic (reasoning) and external data (tool-use), joint training might improve its ability to call the search API but simultaneously degrade its ability to synthesize the search results into a coherent answer, because the gradients for these two tasks push the weights in opposite directions.
Key Novelty
Disentangled Action-Reasoning Tuning (DART)
- Routes reasoning tokens and tool-use tokens to separate, disjoint LoRA adapters while keeping the pre-trained backbone frozen.
- Prevents gradient conflict by ensuring that updates for reasoning logic do not overwrite or interfere with updates for tool execution patterns.
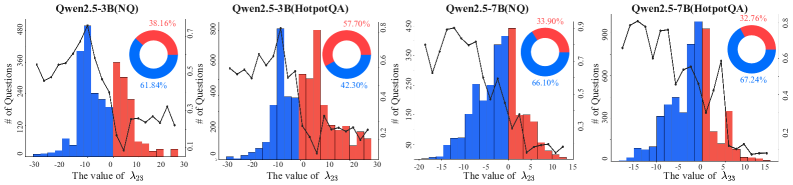
- Introduces a diagnostic framework (LEAS) inspired by variance-based statistics to mathematically quantify the interference between capabilities.
Architecture
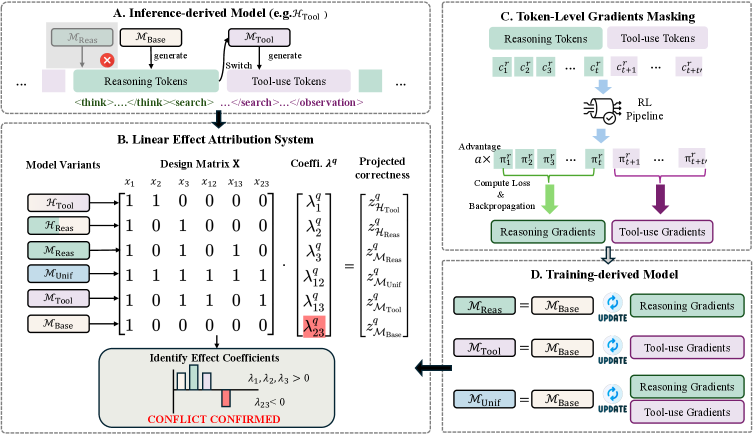
Conceptual flow of DART vs Joint Training. Joint training updates one shared parameter set. DART routes tokens to specific 'Reasoning LoRA' or 'Tool LoRA' based on token type.
Evaluation Highlights
- DART achieves an average Exact Match (EM) score improvement of +6.35% over joint-training baselines across seven benchmarks.
- Matches the performance of specialized multi-agent systems (which use separate models) while using only a single model with lightweight adapters.
- Empirical analysis using LEAS confirms a negative interaction (interference) between capabilities in the majority of test cases.
Breakthrough Assessment
7/10
Strong empirical evidence of a fundamental problem (gradient conflict) in standard Agentic RL, offering a simple but effective architectural solution (DART) that yields consistent gains.