📝 Paper Summary
Multi-call tool use with fixed plan
Constrained Decoding
ToolDec eliminates syntax errors in LLM tool use by enforcing grammar constraints via a Finite State Machine during the decoding process, enabling generalist models to match specialist performance.
Core Problem
Generalist LLMs frequently fail to follow complex syntax constraints when calling tools (e.g., JSON schemas), leading to high error rates even after instruction tuning.
Why it matters:
- Syntax errors prevent models from successfully executing tools, rendering reasoning capabilities useless.
- Existing solutions like fine-tuning or extensive prompting are computationally expensive and struggle to generalize to new tools without retraining.
- Generalist models often achieve 0% accuracy on tool benchmarks purely due to syntactic formatting failures.
Concrete Example:
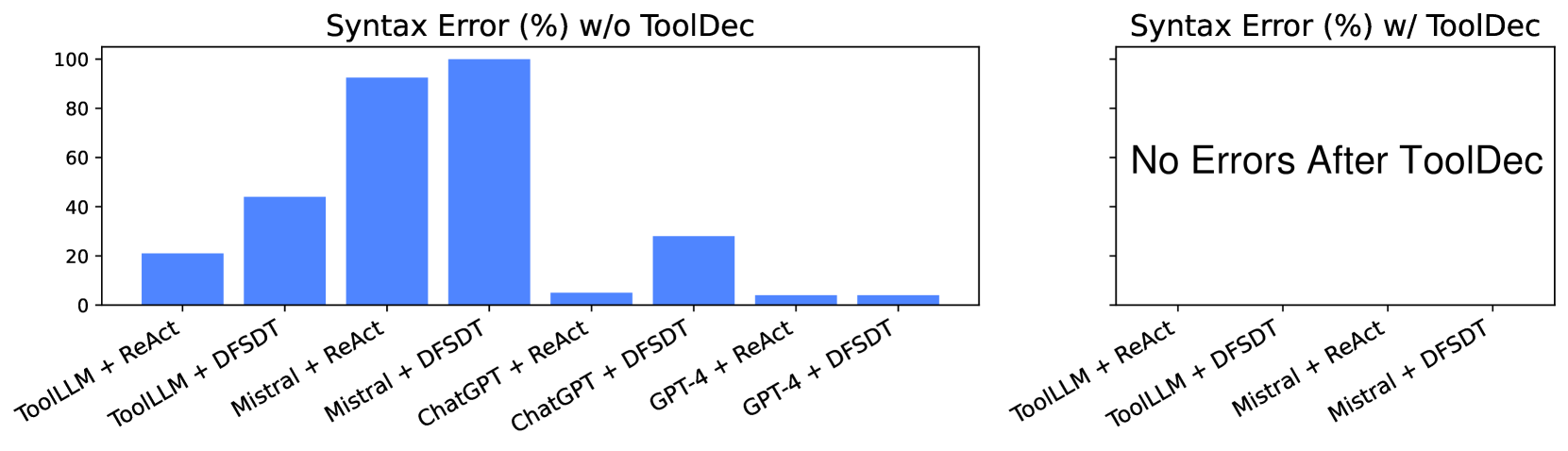
When using an unknown tool in ToolEval, Mistral-Instruct-7B has a syntax error rate over 90%, resulting in 0% accuracy because it fails to format arguments correctly (e.g., generating invalid JSON).
Key Novelty
ToolDec (Finite State Machine Constrained Decoding)
- Constructs a Finite State Machine (FSM) from tool documentation (e.g., JSON schemas) that explicitly defines all valid token sequences.
- During inference, the decoding algorithm masks out all tokens that would violate the tool's syntax, forcing the model to generate only syntactically valid calls.
- Offloads syntax enforcement to the decoding algorithm, allowing the removal of complex syntax instructions from the prompt (prompt compression).
Architecture
A composite view of how ToolDec constructs an FSM from a schema and uses it during inference. Figure 3 shows the FSM structure derived from JSON. Figure 5 shows the decoding process.
Evaluation Highlights
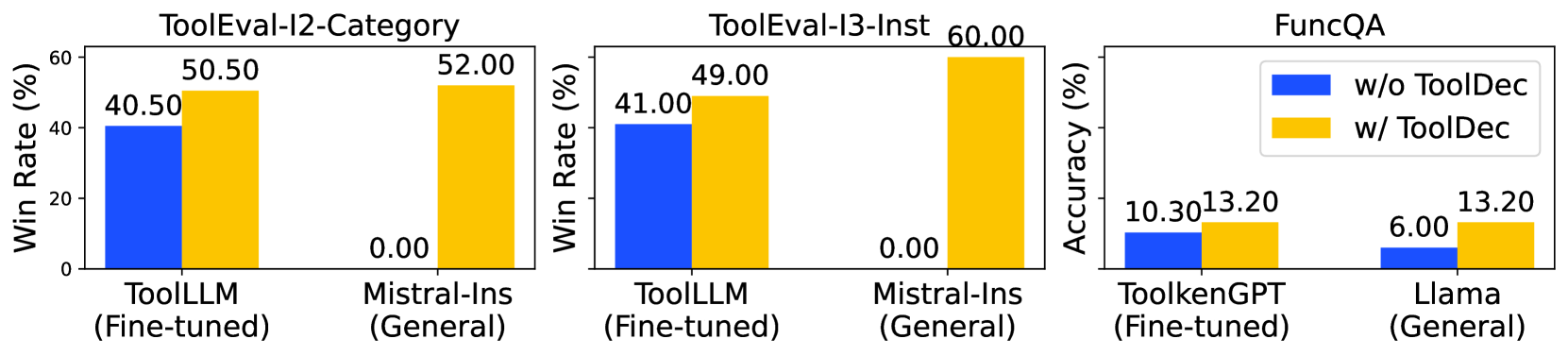
- Improves Mistral-Instruct-7B's accuracy on ToolEval from 0% to ~52%, matching the performance of the fine-tuned specialist ToolLLM.
- Achieves 0 syntax errors across all tested models and benchmarks, compared to >90% error rates for some baselines.
- Reduces prompt length by ~2x on ToolEval by removing syntax examples, while maintaining or improving performance.
Breakthrough Assessment
8/10
Simple yet highly effective intervention. It solves the specific sub-problem of syntax errors completely (0% error rate) without training, allowing generalist models to compete with specialists.