📝 Paper Summary
RL-based Agent
Multi-Turn Tool Use
Reward Modeling
CM2 replaces sparse, verifiable outcome rewards with dense, binary checklist rewards grounded in evidence to train multi-turn tool-using agents in a scalable, LLM-simulated environment.
Core Problem
Training agents for open-ended, multi-turn tasks via RL is difficult because verifiable rewards (e.g., exact match) are often unavailable or insufficient, while maintaining real executable tool environments is engineering-heavy and hard to scale.
Why it matters:
- Realistic agent tasks often lack ground truth answers (e.g., maintaining a helpful tone or asking clarifying questions), making standard RLVR (RL with Verifiable Rewards) inapplicable
- Building and maintaining real APIs for thousands of tools is costly and limits the diversity of training environments, bottling up agent generalization
- Current methods rely on SFT or limited RL, failing to optimize complex, long-horizon interactions that require state tracking and credit assignment
Concrete Example:
In a multi-turn dialogue where a user asks for 'budget-friendly van options', a standard reward model might only check if a van was found. However, the agent might fail to verify the price constraint ($500) before suggesting options, or fail to ask necessary clarifying questions, errors which a binary outcome reward misses but a checklist item like 'Did the agent verify price < $500?' catches.
Key Novelty
Checklist Rewards for Multi-turn Multi-step Agentic Tool Use (CM2)
- Decomposes open-ended judging into fine-grained binary checklist items (e.g., 'Did it call Tool X?', 'Did it check parameter Y?'), each with explicit evidence grounding and metadata
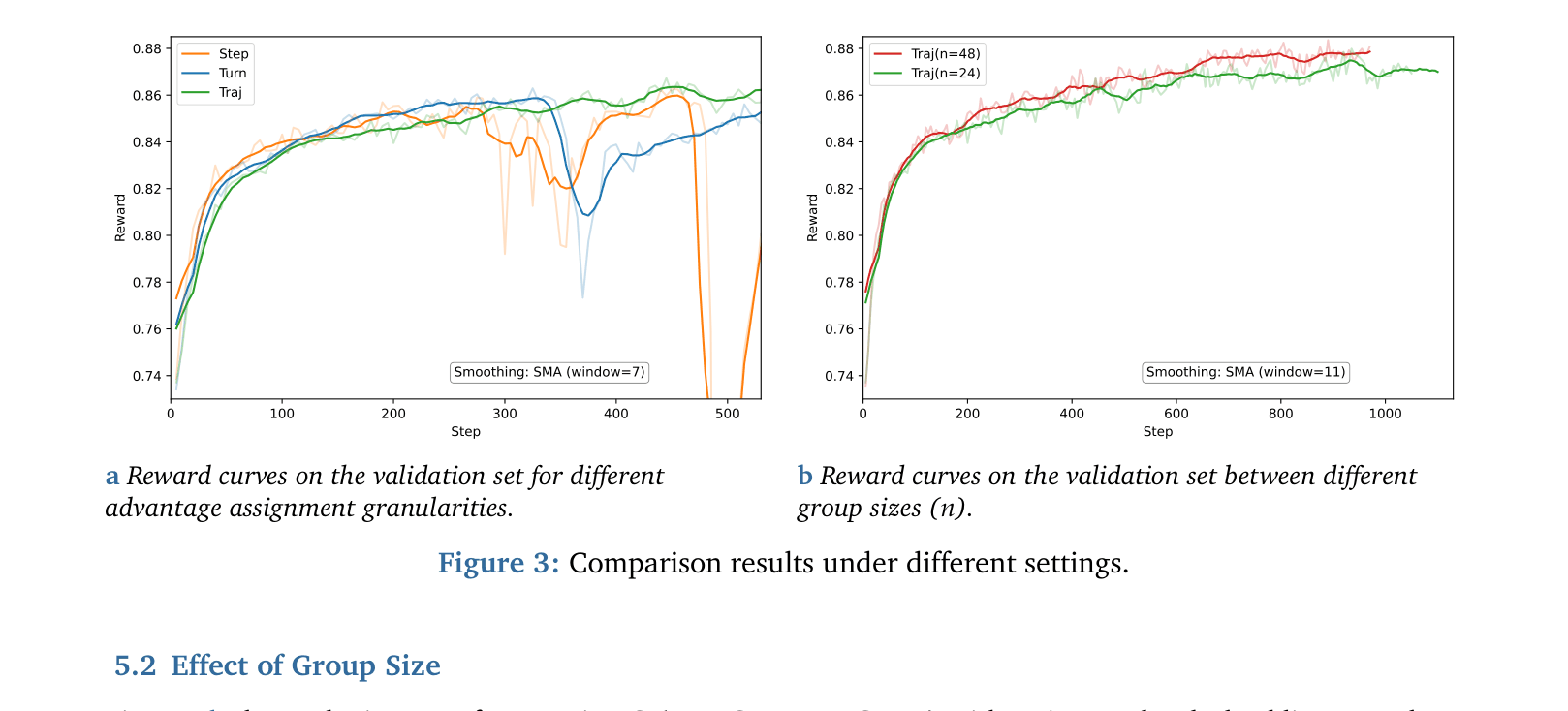
- Adopts a 'Sparse in assignment, Dense in criteria' strategy: uses rich evaluation criteria but assigns rewards at coarser granularity (trajectory-level) to reduce judge noise during optimization
- Uses a hybrid simulator that replays recorded tool outputs when available and falls back to LLM-generated responses otherwise, enabling training on 5,000+ tools without live execution
Architecture
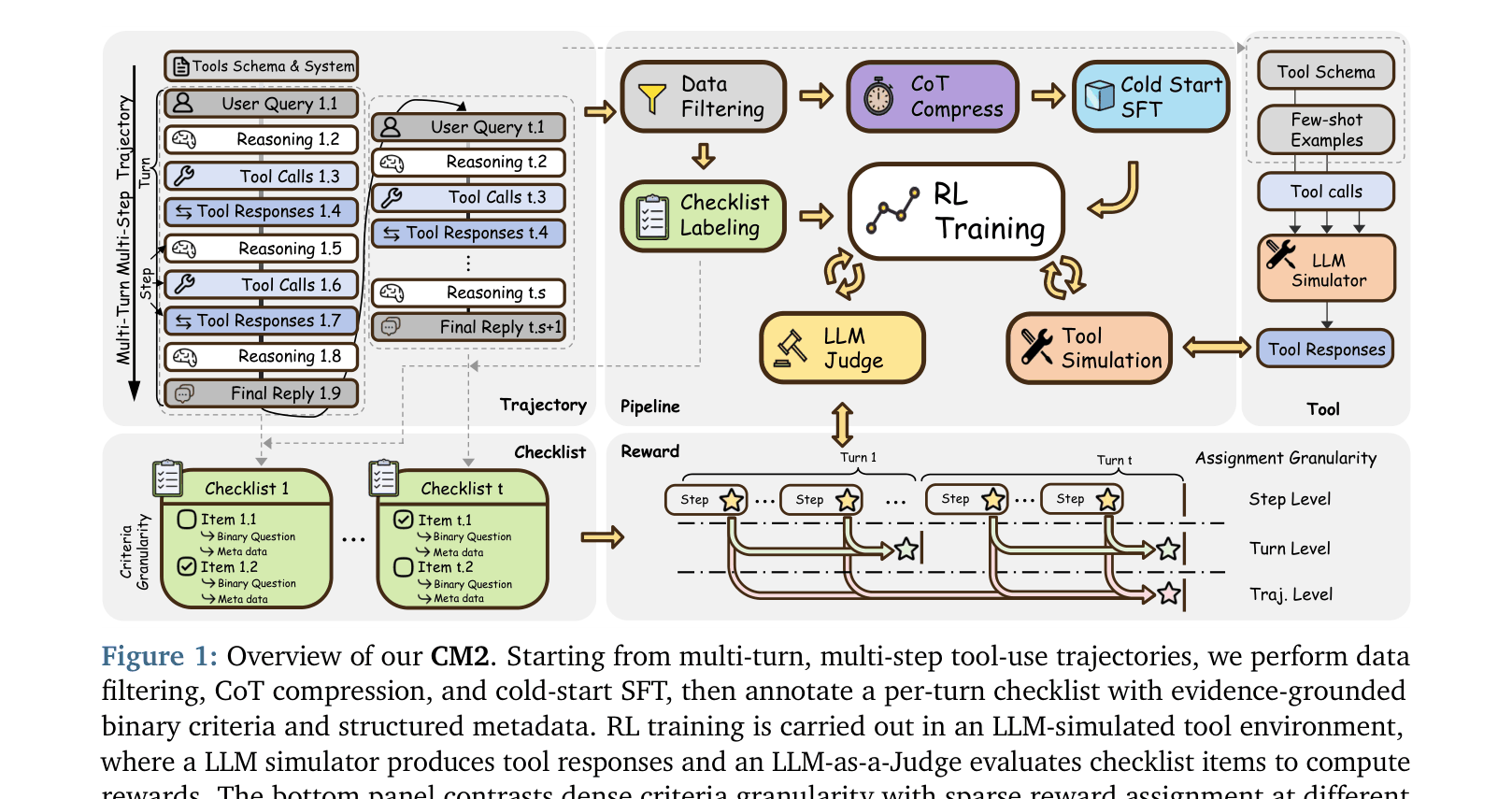
Overview of the CM2 framework, including the data pipeline, checklist labeling, and the RL training loop with simulated tools.
Evaluation Highlights
- +8 points accuracy improvement over SFT counterpart on τ2-Bench (multi-turn tool agent benchmark)
- +10 points overall accuracy on BFCL-V4 (Berkeley Function Calling Leaderboard)
- +12 points overall score on ToolSandbox compared to SFT, outperforming similarly sized open-source baselines
Breakthrough Assessment
8/10
Strong empirical results on major benchmarks and a practical solution to the 'lack of verifiers' problem in agent RL. The shift from scalar rewards to binary checklists with evidence offers a scalable path for open-ended agent training.