📝 Paper Summary
Benchmark
Tool-use agents
Multi-turn w. user interactions
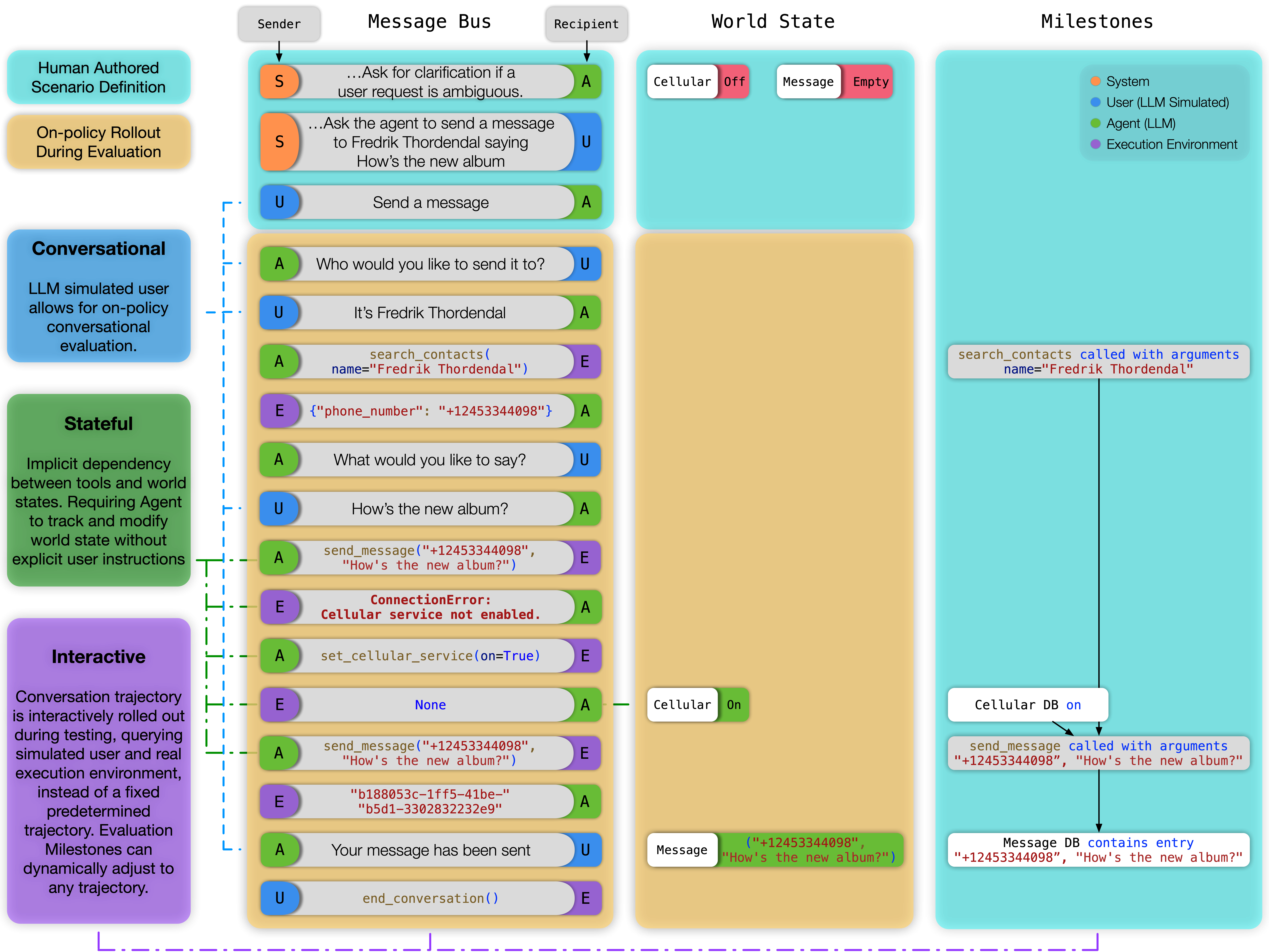
ToolSandbox is a Python-native benchmark for tool-use agents that evaluates stateful, conversational interactions using an LLM-simulated user and a flexible milestone-based scoring system.
Core Problem
Existing tool-use benchmarks rely on stateless web APIs, single-turn prompts, or fixed off-policy trajectories, failing to capture the complexity of real-world scenarios where tools depend on changing world states and users interact conversationally.
Why it matters:
- Real-world tasks often involve implicit dependencies (e.g., turning on WiFi before searching) that current stateless benchmarks miss.
- Static or single-turn evaluations cannot measure an agent's ability to correct errors or handle follow-up clarifications in a live session.
- Fixed-trajectory benchmarks (like API-Bank) penalize valid alternative solutions that achieve the same goal through different steps.
Concrete Example:
A user asks to 'send a message'. If cellular service is off, the tool fails. A capable agent must catch the error, turn on service (changing the world state), and retry. Current benchmarks would simply mark the initial failure as a zero or ignore the state dependency entirely.
Key Novelty
Stateful, Interactive World with Milestone-Based Scoring
- Introduces 'Stateful Tools' where execution depends on a persistent world state (e.g., location, settings) that agents must track and modify.
- Uses a 'Milestone and Minefield' evaluation system that scores trajectories based on reaching necessary intermediate states (DAG-based) rather than matching a rigid reference sequence.
- Deploys a 'User Simulator' enhanced with Knowledge Boundaries and Demonstrations to enable on-policy conversational evaluation where the user reacts to the agent's specific actions.
Architecture
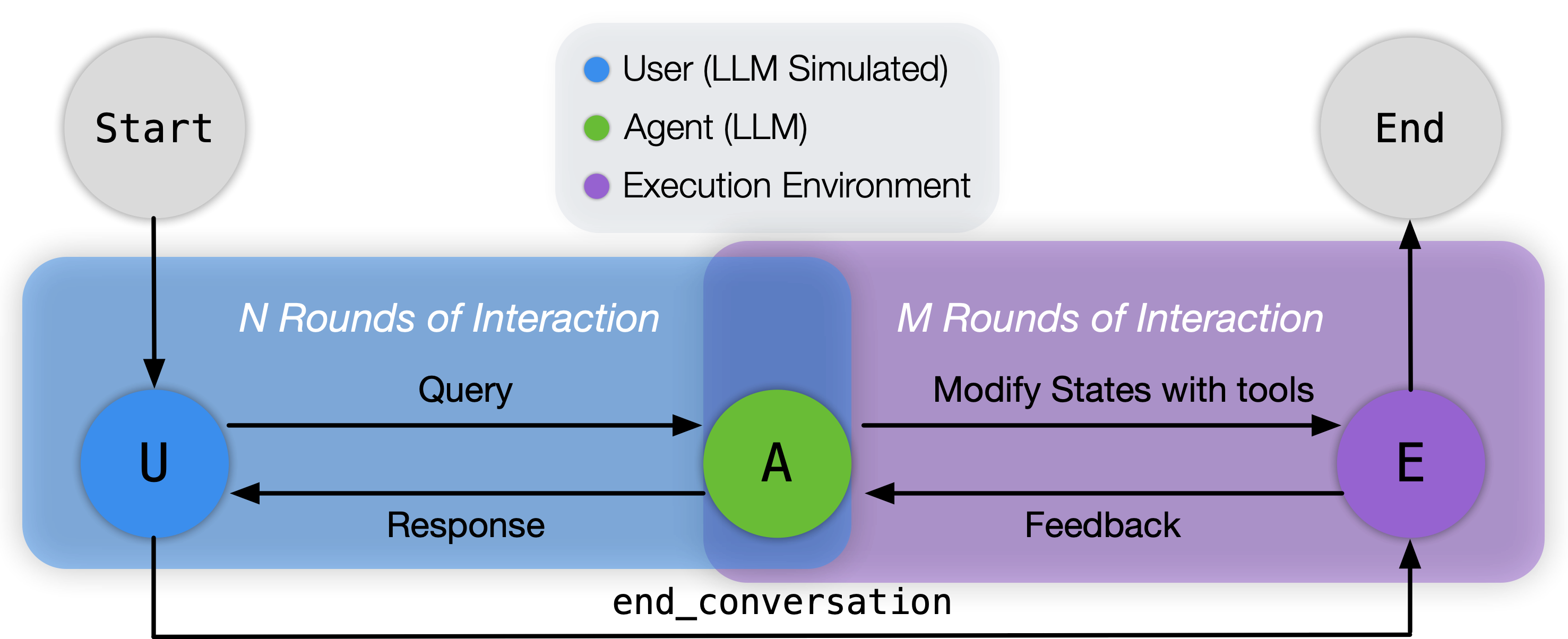
The overall workflow of the ToolSandbox evaluation framework, illustrating the interaction loop between User, Agent, and Execution Environment.
Evaluation Highlights
- State Dependency tasks cause a massive performance drop: GPT-4o drops from ~85% on easier tasks to 42.1% on nested state dependency scenarios.
- Insufficient Information scenarios reveal high hallucination rates: even top models fail to identify unsolvable tasks, with pass rates often near 0% for some models.
- Proprietary models (GPT-4o) significantly outperform open weights models (Llama-3-70B-Instruct) by large margins (e.g., +30-40%) on complex stateful tasks.
Breakthrough Assessment
8/10
Significantly advances tool-use evaluation by moving beyond static API calls to stateful, interactive environments. The milestone scoring system solves the 'multiple valid paths' problem in dialog evaluation.