📝 Paper Summary
Multimodal Agents
Tool Use / Tool Learning
Visual Instruction Tuning
LLaVA-Plus extends a large multimodal model by training it to actively select and use external vision tools (like detectors and generators) to answer complex visual user requests.
Core Problem
Existing Multimodal Agents either lack broad skills (segmentation, generation) or rely on text-only LLMs to call tools without seeing the image, leading to poor planning and context grounding.
Why it matters:
- Standard LMMs (Large Multimodal Models) cannot perform specialized tasks like editing images or precise segmentation without external help.
- Tool-chaining methods (like Visual ChatGPT) use text prompts to call tools, but because the planner cannot see the image, it often hallucinates or invokes incorrect tools for the visual context.
Concrete Example:
In a tool-chaining system, if a user asks about the location of a 'frisbee' in an image, a text-only planner might fail to invoke a detector if the caption misses the frisbee. LLaVA-Plus sees the image directly, recognizes the need for detection, calls the tool, and accurately reports the coordinates.
Key Novelty
End-to-End Visual Tool Learning (LLaVA-Plus)
- Integrates a 'Skill Repository' of vision experts (tools) directly with an LMM that acts as a planner, trained to output structured 'Thought', 'Action', and 'Value' sequences.
- Unlike prior tool agents, the planner sees the raw image during the decision-making process, allowing visual signals to guide which tool is selected.
- Introduces a new pipeline for curating 'skill-oriented' multimodal instruction data where the model learns to invoke tools and summarize their outputs.
Architecture
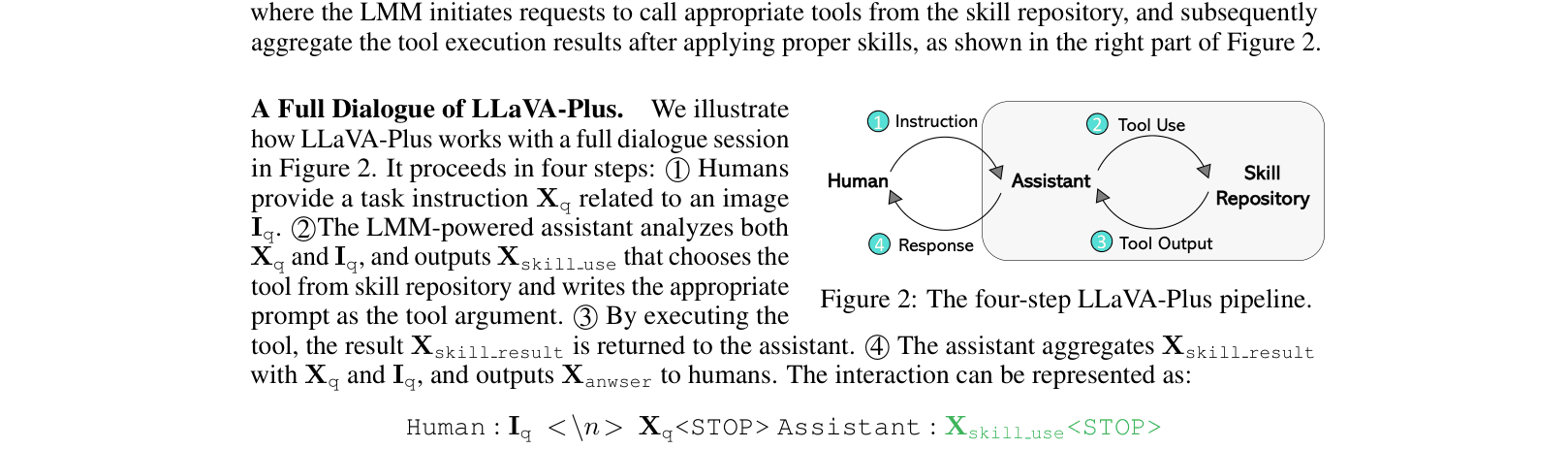
The four-step workflow of LLaVA-Plus: Human input, Assistant planning (tool selection), Tool execution, and Assistant response generation.
Evaluation Highlights
- Achieves state-of-the-art Elo rating of 1203 on VisIT-Bench, outperforming the base LLaVA model (1095) by over 100 points.
- Surpasses commercial systems on the LLaVA-Bench (Tool Use) dataset, scoring 82.3 compared to Bing Chat's 70.2 and Bard's 76.3.
- Outperforms MM-REACT (a tool-augmented LLM) on tool-use benchmarks (82.3 vs 76.5), validating the benefit of image-grounded planning.
Breakthrough Assessment
8/10
Significant step in making LMMs general-purpose agents. Bridging the gap between monolithic LMMs and modular tool use via instruction tuning is highly effective and practical.
