📝 Paper Summary
Tool-use post-training
Generative tool selection
ToolWeaver replaces unique tool tokens with hierarchical code sequences generated via collaborative-aware quantization, enabling LLMs to scale to thousands of tools while learning collaborative relationships from dense code co-occurrences.
Core Problem
Assigning a unique token to every tool causes vocabulary explosion and creates a semantic bottleneck, as the model must infer relationships from the sparse co-occurrence of isolated IDs.
Why it matters:
- Linear vocabulary growth (one token per tool) is unsustainable for massive tool libraries (e.g., 47,000 tools), requiring huge memory and disrupting pre-trained knowledge
- Sparse co-occurrence of unique IDs prevents models from learning that certain tools (e.g., Weather and Air Quality) should work together, leading to incomplete reasoning
- Existing retrieval methods are complex and disconnected from the LLM's reasoning, while current generative methods fail to generalize to new tools without retraining embeddings
Concrete Example:
For the query 'is it a good day to take my kid to the park?', a model needs both 'Realtime Weather' and 'Air Quality'. If these are represented as isolated tokens <Tool_42> and <Tool_99> that rarely appear together, the model may select Weather but miss Air Quality. ToolWeaver groups them under a shared parent code (e.g., <Conditions>) so the model learns the category association.
Key Novelty
Collaborative-Aware Structured Tokenization
- Represents each tool not as a single ID, but as a sequence of discrete codes (e.g., <T1_1><T2_1>) from hierarchical codebooks, reducing vocabulary expansion from linear to logarithmic
- Injects collaborative signals (tool co-usage patterns) directly into the tokenization process using a Graph Laplacian regularizer, forcing functionally related tools to share code prefixes
- Solves the 'index collision' problem in quantization using Optimal Transport (Sinkhorn-Knopp) to ensure every tool has a unique code sequence without breaking semantic structure
Architecture
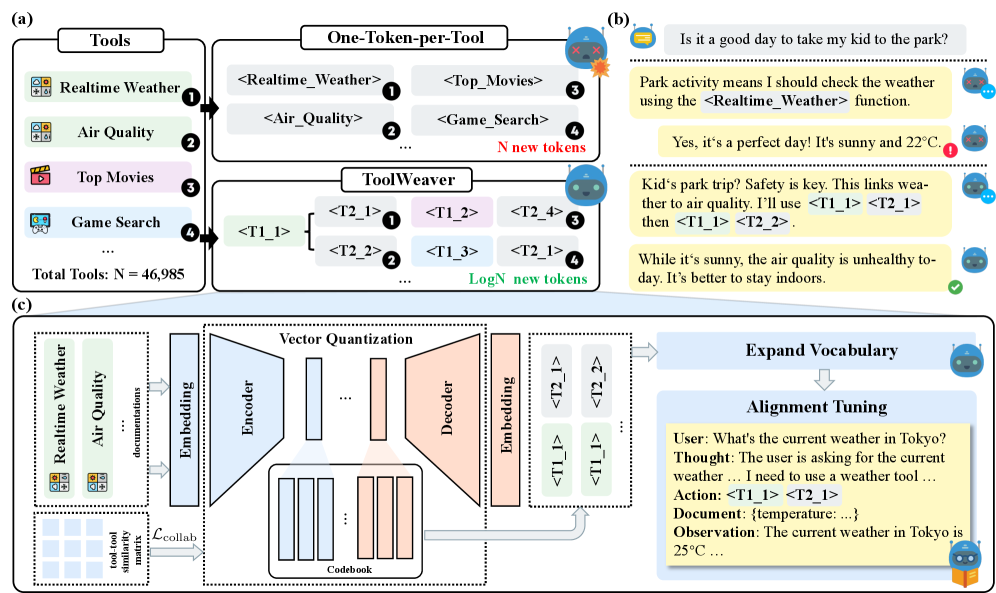
The structured tokenization process of ToolWeaver. It visualizes how a tool is mapped to a sequence of codes from multiple codebooks.
Breakthrough Assessment
8/10
Addresses the fundamental scalability limit of generative tool use (vocabulary explosion) while simultaneously solving the semantic sparsity problem. The shift from atomic to compositional tool tokens is a significant architectural advance.