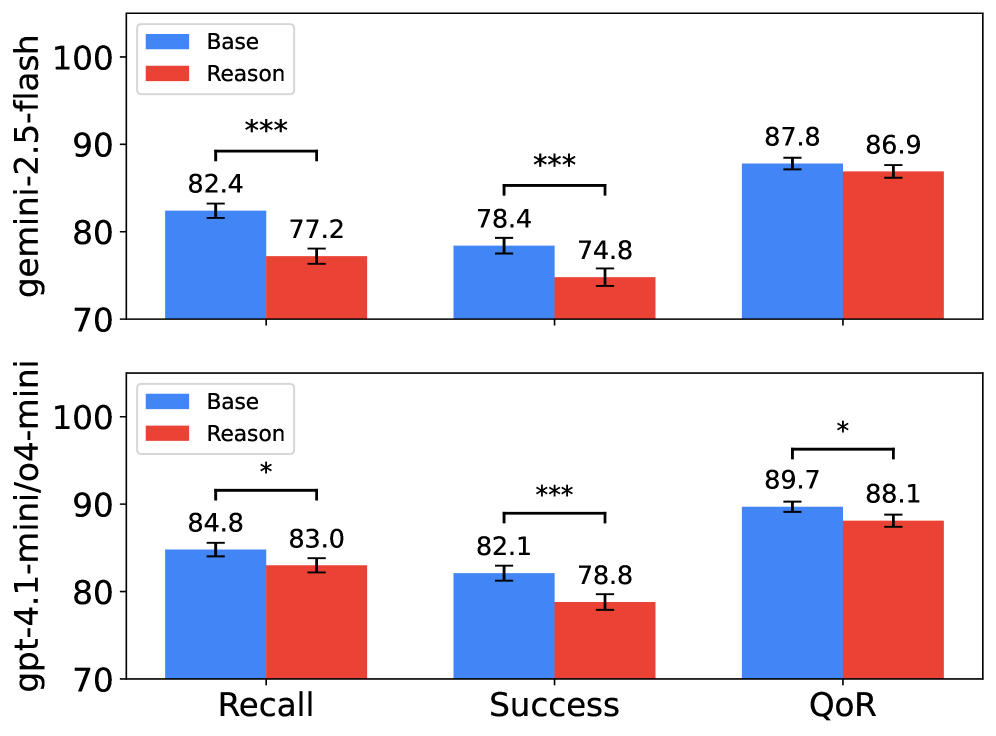
📝 Paper Summary
Synthetic data generation
Tool-use post-training
Agentic framework
ToolGrad generates high-quality tool-use datasets by iteratively constructing valid tool execution chains using textual feedback before synthesizing the corresponding user queries, achieving higher efficiency than query-first approaches.
Core Problem
Existing tool-use dataset generation methods first synthesize a user query and then use an agent (like DFS) to search for a solution, which is inefficient and error-prone.
Why it matters:
- The standard 'query-first' approach relies on expensive agent exploration (trial and error) to find valid tool paths, wasting computational resources
- Agent exploration has no guarantee of success, leading to low pass rates and discarded data during the generation process
- Current methods struggle to scale because high-quality human annotation is impractical and agent-based search is computationally costly
Concrete Example:
In ToolBench, a hypothetical user instruction is generated first, then a DFS agent tries to solve it. This often fails or requires many steps. ToolGrad inverts this: it builds a valid chain of API calls (e.g., searching for a movie, then getting its rating) first, ensuring validity, and *then* writes the user query 'What is the rating of movie X?'.
Key Novelty
Answer-First Iterative Tool-Chain Construction via Textual Gradients
- Inverts the standard data generation paradigm by building the 'answer' (valid tool-use chain) first and synthesizing the 'question' (user query) last
- Uses an iterative agentic loop inspired by ML optimization: selects APIs to augment the current workflow based on execution feedback (acting as textual 'gradients') rather than random exploration
Architecture
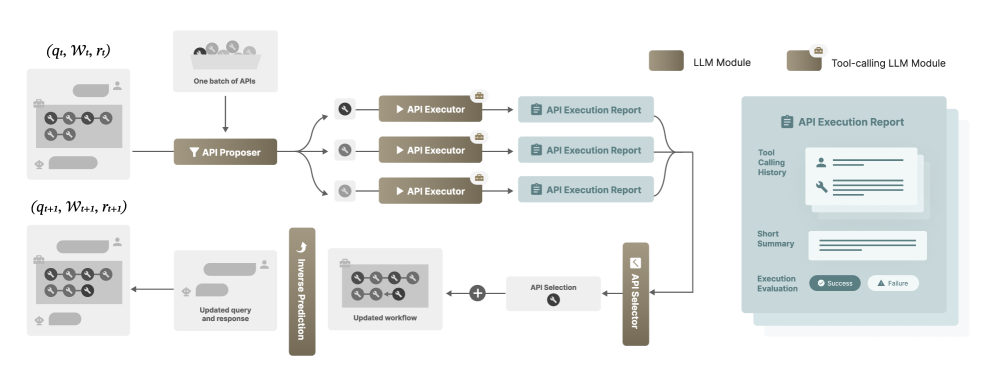
The iterative pipeline of ToolGrad for one generation step.
Evaluation Highlights
- Achieved 100% data generation pass rate compared to 63.8% for the DFS-based baseline in ToolBench
- Reduced generation cost significantly: 45.9 LLM calls per sample vs. 64.5 for baseline, and <30 tool calls vs. 34.3
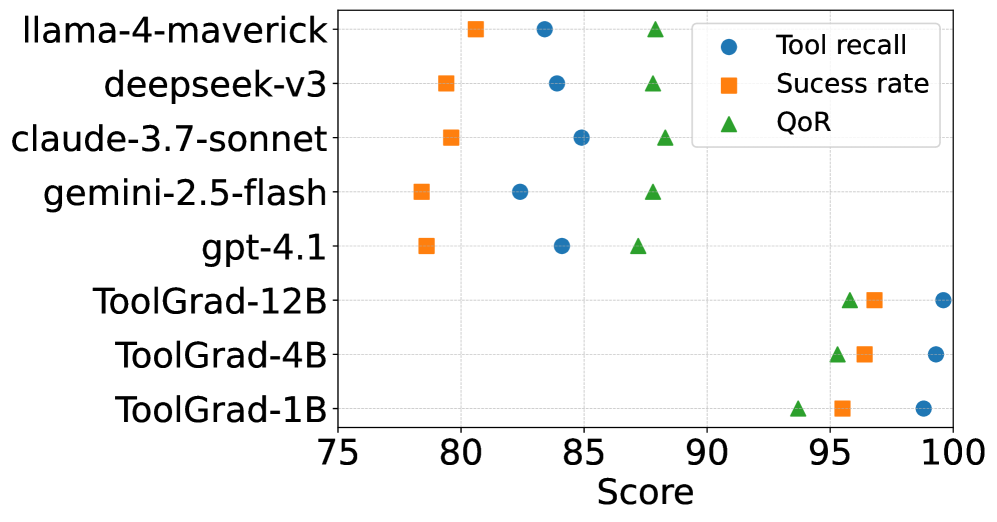
- Fine-tuned 1B model achieves ~99% tool recall, outperforming proprietary models like GPT-4.1 (~85%) on the test set
Breakthrough Assessment
8/10
Significantly improves data generation efficiency (100% pass rate) and quality. The 'answer-first' paradigm combined with 'textual gradients' is a clever structural innovation for synthetic data.