📝 Paper Summary
Multi-agent tool use
Reinforcement Learning for Reasoning
MSARL decouples mathematical reasoning from tool execution using two specialized agents—a Reasoner and a Helper—trained via collaborative reinforcement learning to reduce cognitive interference and improve accuracy.
Core Problem
Single-agent systems combining high-level reasoning with low-level tool execution suffer from cognitive load interference, where managing code generation/interpretation degrades the quality of the reasoning itself.
Why it matters:
- Coupling complex logic with precise tool syntax forces models to juggle competing cognitive demands, leading to unstable outputs
- Current approaches relying on single-agent SFT (Supervised Fine-Tuning) fail to optimize the interaction between reasoning and tool use
- Intermediate logical steps are often degraded when models attempt to interleave code execution, as evidenced by performance drops in medium-difficulty math problems
Concrete Example:
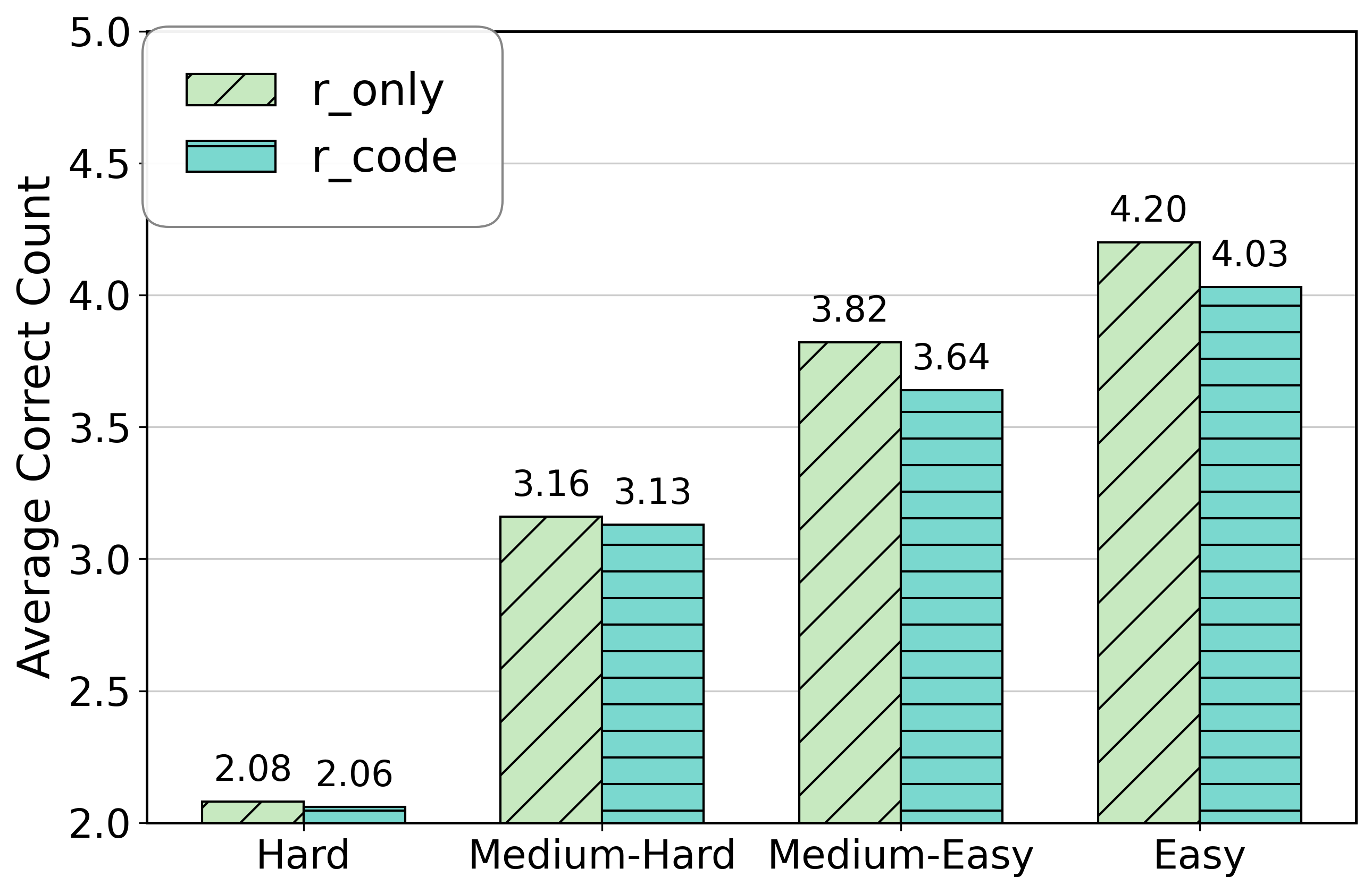
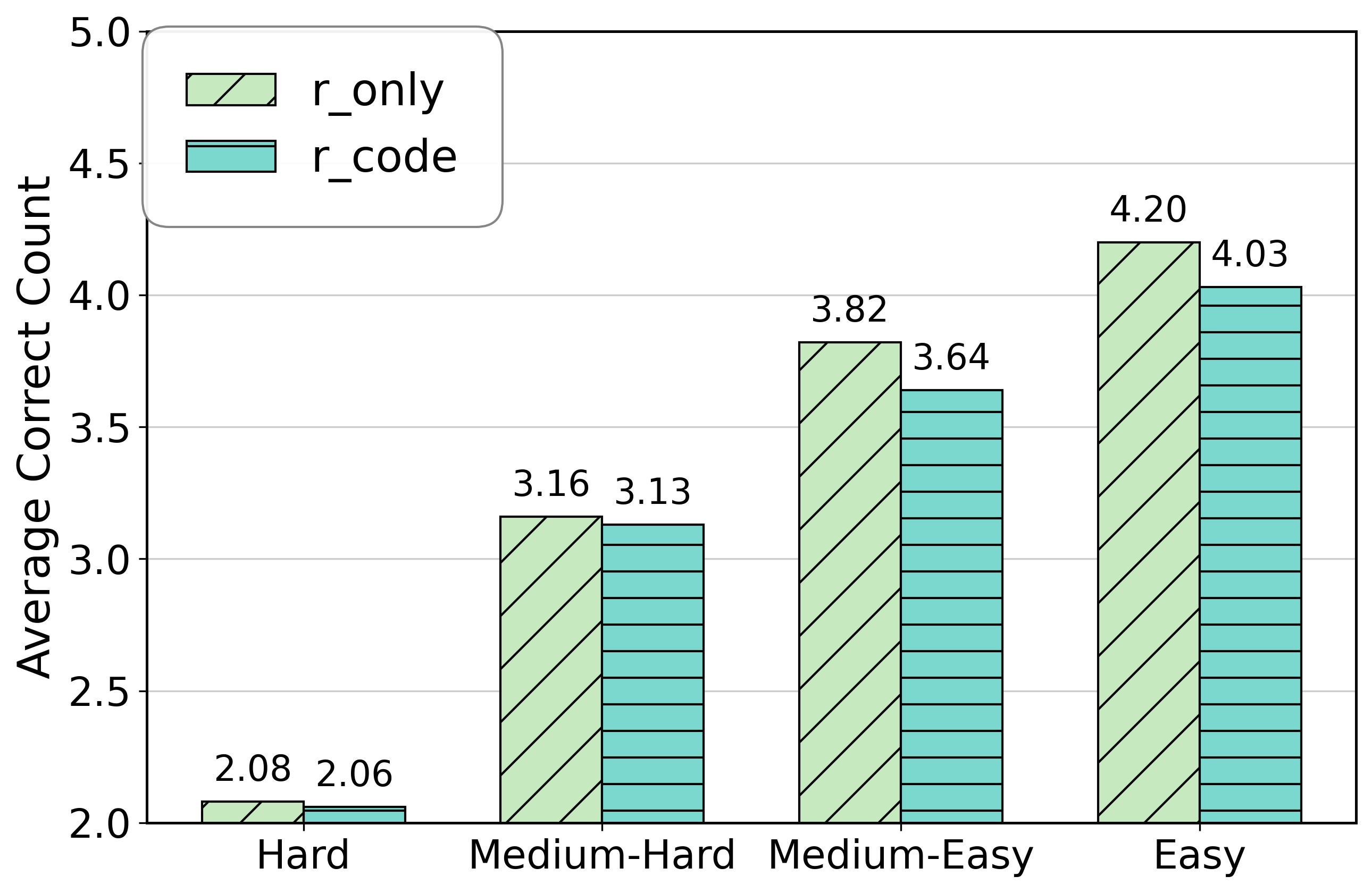
In a pilot study on MATH-500, a single agent instructed to use code ('r_code') performed worse than a reasoning-only agent ('r_only') on Medium-Easy problems (-0.18 accuracy gap), showing that the burden of tool management disrupted the problem-solving logic.
Key Novelty
Multi-Small-Agent Reinforcement Learning (MSARL)
- Explicitly decouples roles into a 'Reasoner' (planning, logic) and a 'Helper' (tool output interpretation/condensing) to prevent cognitive overload
- Uses a collaboration-oriented reward mechanism where the 'Helper' is rewarded based on whether the 'Reasoner' successfully solves the problem using the Helper's output
- Employs a hierarchical RL framework (based on GRPO) to jointly optimize both agents, treating the Helper's interpretation as a critical milestone
Architecture
The MSARL framework illustrating the interaction between the Reasoner and Helper agents.
Evaluation Highlights
- Pilot study reveals a significant accuracy drop of 0.18 (18 percentage points) on Medium-Easy MATH-500 problems when forcing a single agent to use code versus reasoning alone
- Accuracy gaps ranging from 0.02 to 0.18 observed across all difficulty levels for single-agent tool integration, confirming the 'cognitive interference' hypothesis
Breakthrough Assessment
7/10
Identifies and quantifies 'cognitive interference' in single-agent tool use and proposes a novel multi-agent RL solution. (Score limited as final performance tables are not in the provided text snippet).