📝 Paper Summary
Multi-agent tool use
Agent coordination
ConAgents decomposes complex tool-use tasks into three specialized agents (Grounding, Execution, Review) that cooperate via iterative feedback loops, enabling self-correction and better performance than single-agent pipelines.
Core Problem
Existing single-agent tool-use methods follow rigid pipelines that lack flexibility to correct errors mid-execution and struggle to master diverse sub-skills (planning vs. coding) simultaneously.
Why it matters:
- Rigid pipelines (Plan → Act) often fail propagate errors forward without correction, leading to cascading failures in multi-step tasks
- Forcing one LLM to handle planning, coding, and reflection simultaneously overloads its context and capabilities, causing performance degradation on complex tasks
- Open-source models struggle more with monolithic agent roles compared to stronger closed-source models like GPT-4
Concrete Example:
If a tool execution fails due to a wrong argument (e.g., searching for a movie with the wrong date format), a standard ReAct agent might just retry blindly or crash. In ConAgents, the Review Agent spots the error in the execution code, explains the format mismatch to the Execution Agent, which then corrects the code dynamically.
Key Novelty
ConAgents: Cooperative and Interactive Agents Framework
- Decomposes the tool-use process into three distinct roles: Grounding (planning), Execution (writing code/calling tools), and Review (critiquing and correcting)
- Introduces two communication protocols: 'Automatic' (always review every step) and 'Adaptive' (review only when errors occur), allowing dynamic self-correction
- Uses 'Specialized Action Distillation' (SPAN) to train smaller open-source models on these specific roles using clustered, high-quality trajectories from GPT-4
Architecture
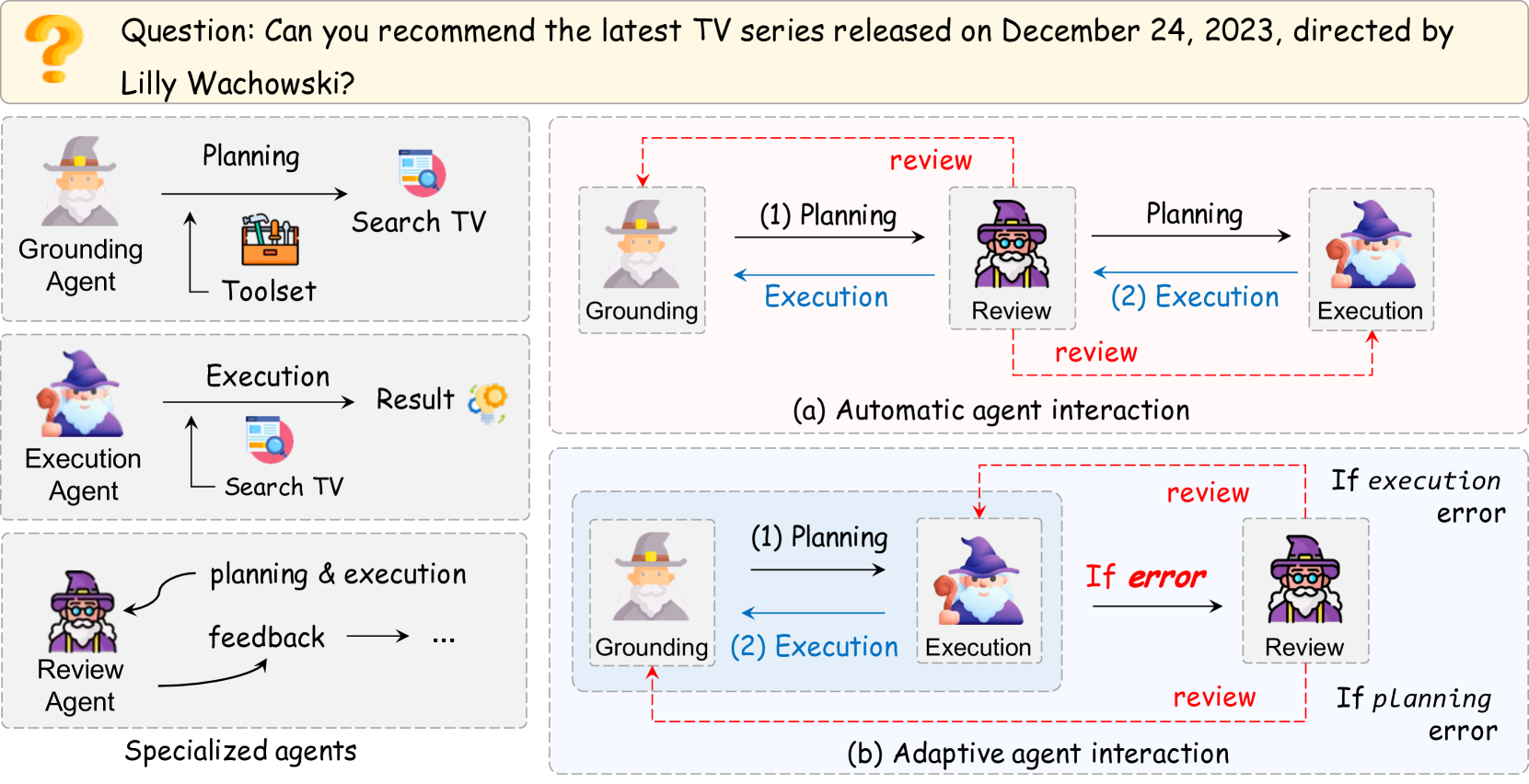
The ConAgents framework showing the interaction between Grounding, Execution, and Review agents under two protocols.
Evaluation Highlights
- Outperforms state-of-the-art baselines (e.g., DFSDT, ReAct) by up to +14% Success Rate on ToolBench and RestBench
- Specialized Action Distillation (SPAN) enables Llama-2-7B to achieve strong performance with only 500 training examples per agent
- Ablation studies show the Review Agent significantly boosts performance (+6% success rate) by catching errors before they propagate
Breakthrough Assessment
7/10
Strong empirical results and a logical decomposition of agent roles. The distillation strategy for open-source models is practical. While multi-agent reflection is becoming common, the specific protocols and distillation method offer solid contributions.