📝 Paper Summary
Multi-call tool use with flexible plan
Prompt-based w. optimization
ART enables frozen LLMs to solve new tasks by retrieving demonstrations from related tasks that teach the model how to decompose problems and use external tools without task-specific training.
Core Problem
Existing Chain-of-Thought (CoT) and tool-use methods typically require hand-crafting task-specific prompts or fine-tuning, making them difficult to scale to new, unseen tasks.
Why it matters:
- Current approaches struggle to generalize zero-shot to complex multi-step reasoning tasks without explicit human supervision.
- Manually writing CoT prompts and tool-use scripts for every new task is labor-intensive and fragile.
- LLMs have severe limitations in math and up-to-date knowledge that tools can solve, but integrating them usually requires task-specific engineering.
Concrete Example:
In a physics QA task, a standard LLM might hallucinate a formula. ART retrieves a program from a related task (e.g., math word problems) that demonstrates using a search engine to find formulas and a Python calculator to compute values, allowing the LLM to correctly solve the physics problem zero-shot.
Key Novelty
Automatic Reasoning and Tool-use (ART)
- Maintains a library of 'programs'—structured demonstrations of multi-step reasoning and tool use—for a small seed set of tasks.
- When given a new task, retrieves programs from related seed tasks to construct a dynamic few-shot prompt.
- Uses a structured query language that allows the frozen LLM to pause generation, call external tools (search, code), and resume reasoning automatically.
Architecture
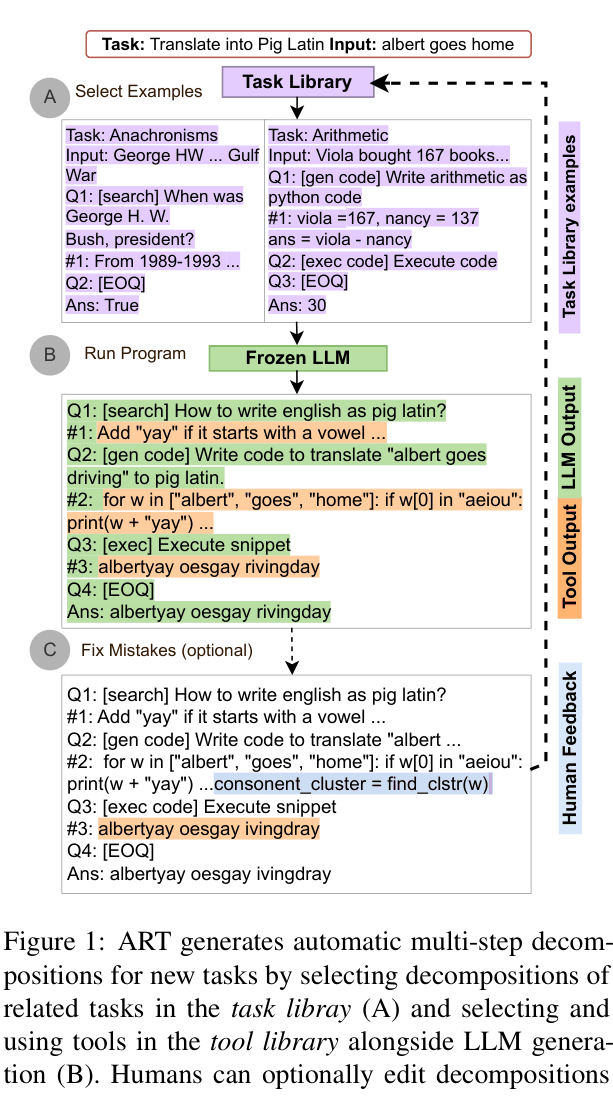
The ART framework workflow: Selecting demonstrations from a Task Library, generating reasoning steps with a Frozen LLM, pausing for Tool Use, and optional Human Feedback.
Evaluation Highlights
- +12.3 percentage points improvement from tool-use on unseen BigBench test tasks compared to ART without tools.
- Matches or outperforms automatic Chain-of-Thought (Auto-CoT) on 32/34 BigBench tasks and all MMLU tasks, averaging >22 percentage points higher.
- Surpasses best published GPT-3 results by over 20 percentage points on select tasks when incorporating minimal human feedback (correcting 5 examples).
Breakthrough Assessment
8/10
Significantly advances zero-shot tool use by removing the need for task-specific prompt engineering. The framework's extensibility via human feedback is a strong practical contribution.
