📝 Paper Summary
Memory recall
Tool-use post-training
A context compression framework for tool-using models that combines selective retention of key terms (like names) with block-wise soft compression to achieve high compression ratios without losing functional precision.
Core Problem
Tool documentation is lengthy and static, consuming valuable context window space and slowing decoding. Existing soft compression methods cause 'key information loss' (e.g., hallucinating parameter names) and lack flexibility for variable documentation lengths.
Why it matters:
- Lengthy documentation for multiple tools can easily exceed input windows (thousands of tokens), making complex tool-use prohibitive
- Standard compression treats all text equally, but in tool use, a misspelled parameter name causes immediate execution failure, unlike general text summarization where approximation is acceptable
- Existing methods typically compress to fixed lengths, which is inefficient for short tools and lossy for long ones
Concrete Example:
When compressing documentation for an API, a standard soft compressor might summarize the functionality well but Hallucinate the parameter name 'user_id' as 'uid'. Consequently, the generated function call fails during execution.
Key Novelty
Selective and Block-wise Context Compression
- Selective Compression: Identifies 'key information' (tool/parameter names) and preserves them as raw text tokens, while compressing descriptive text into soft vectors
- Block Compression: Splits documentation into chunks based on a target compression ratio rather than a fixed target length, allowing flexible handling of diverse document sizes
Architecture
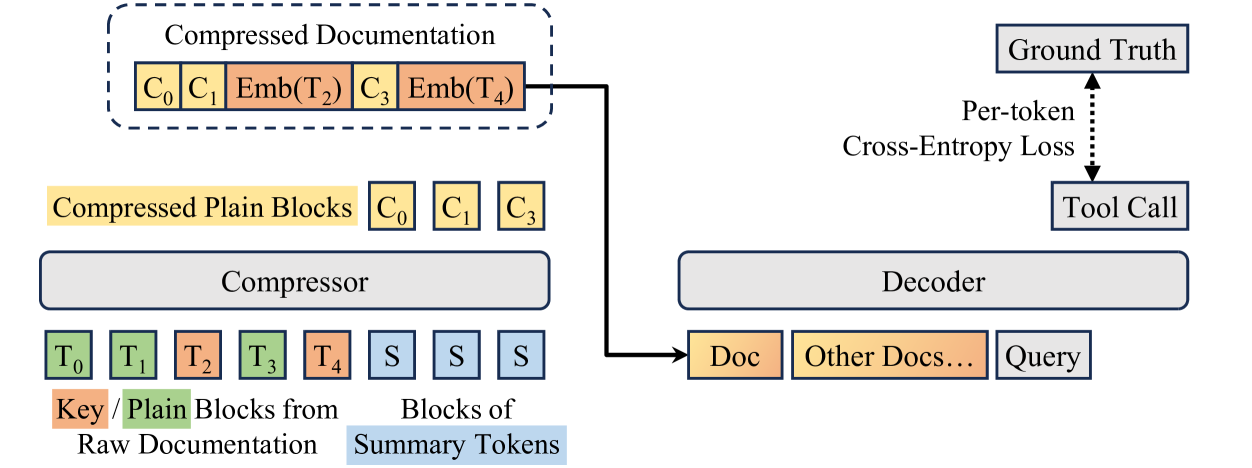
The concise and precise context compression framework, illustrating the interaction between Selective Compression and Block Compression.
Evaluation Highlights
- Achieves comparable performance to the upper-bound baseline (uncompressed full context) under up to 16x compression ratio on API-Bank and APIBench
- Selective compression significantly mitigates key information loss compared to standard soft compression
- Block compression introduces no additional performance loss compared to overall compression while enabling length flexibility
Breakthrough Assessment
7/10
Addresses a critical bottleneck in agentic AI (context length) with a practical, domain-aware solution. The 16x compression ratio with negligible loss is significant, though the method relies on known soft-prompting techniques.