📝 Paper Summary
RL-based tool use
Code Interpreter integration
ReTool trains language models to autonomously decide when and how to use a code interpreter for math problems by integrating real-time code execution into the reinforcement learning rollout loop.
Core Problem
Text-based reasoning models struggle with precise calculations and symbolic manipulation, while existing tool-use methods rely on supervised imitation that fails to teach strategic, adaptive tool invocation.
Why it matters:
- Pure textual Chain-of-Thought often contains calculation errors or hallucinations in complex math problems
- Supervised fine-tuning for tool use relies on fixed patterns, leading models to misuse tools or fail when brittle heuristics break
- Current reasoning models (like DeepSeek R1) excel at logic but lack the reliability of formal code execution for numeric verification
Concrete Example:
In a complex equation solving task, a standard text-reasoning model might hallucinate an incorrect arithmetic step (e.g., calculating 234 * 89 wrong). ReTool, instead, learns to recognize the calculation need, write a Python script to compute it, execute the script, and use the precise output `20826` to continue reasoning.
Key Novelty
Outcome-Driven Tool-Augmented Reinforcement Learning
- Integrates a sandbox code interpreter directly into the PPO exploration phase, allowing the model to generate code, execute it, and see the results (or errors) before generating the next step
- Uses rule-based outcome rewards (final answer correctness) rather than process supervision, enabling the model to self-discover strategies for *when* to invoke tools versus reasoning in text
Architecture
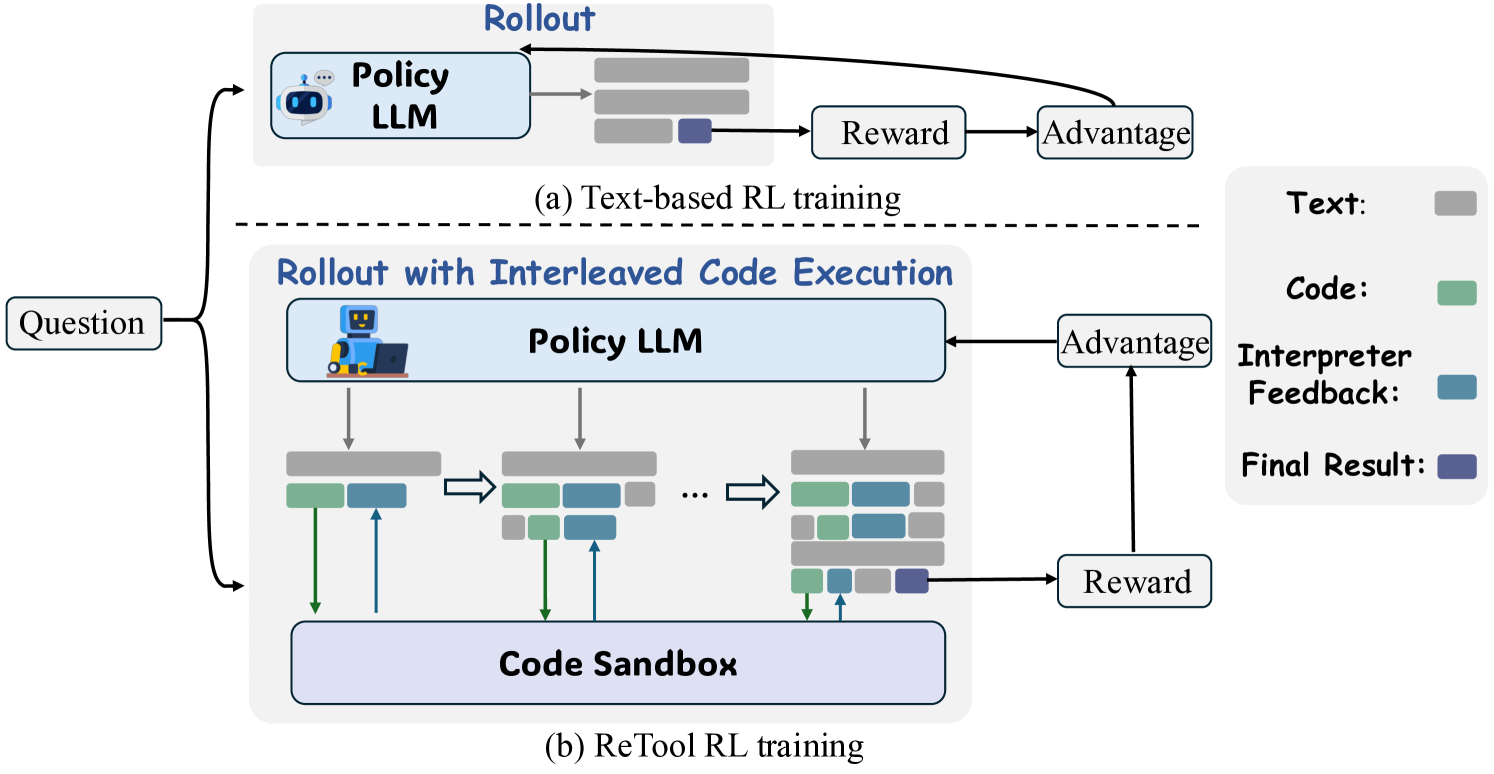
Comparison of Text-based Rollout vs. Interleaved Code Execution Rollout
Evaluation Highlights
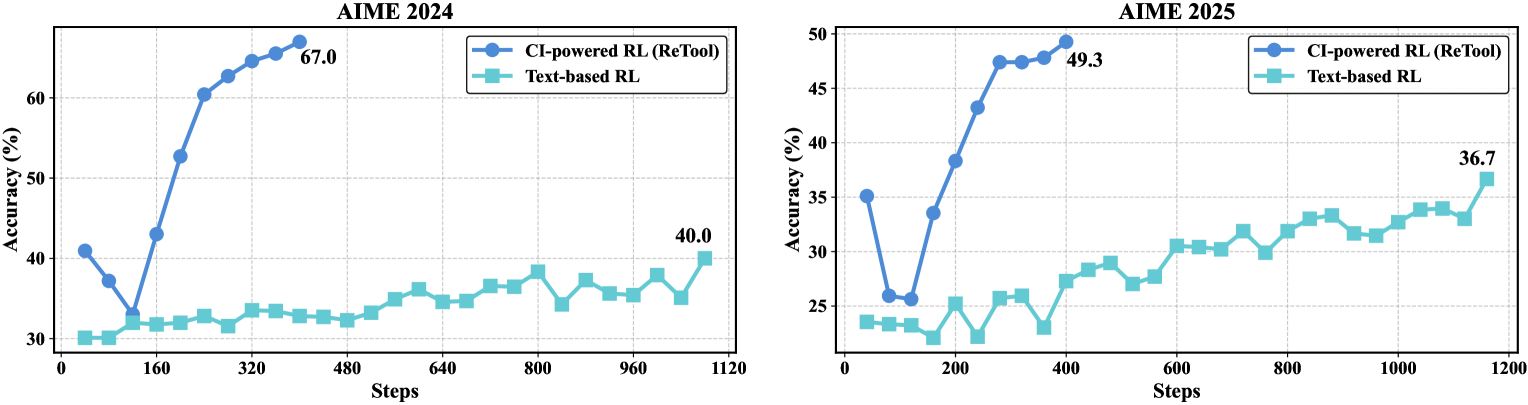
- Achieves 67.0% accuracy on AIME 2024, outperforming the text-based RL baseline (40.0%) by 27 percentage points using the same base model
- Reduces response length by approximately 40% compared to pre-training, indicating more efficient reasoning via computational offloading
- Surpasses OpenAI o1-preview by 27.9% in extended settings (ReTool-32B at 72.5% accuracy)
Breakthrough Assessment
8/10
Significant efficiency and performance gains by successfully integrating tool execution into the RL update loop. Demonstrates emergent 'aha moments' in tool strategy without explicit process supervision.