📝 Paper Summary
Robotic Manipulation
Imitation Learning from Single Demonstration
Tool Use
Grasp Generalization
This method enables robots to learn interactive tool-use policies from a single human demonstration by warping the demonstrated grasp to new tool shapes via non-rigid registration and using it to guide Reinforcement Learning.
Core Problem
Robotic tool use with multi-fingered hands has a high-dimensional action space and requires adapting grasps to diverse tool shapes, which typically demands prohibitive amounts of demonstration data.
Why it matters:
- Standard Imitation Learning requires vast datasets covering every object variation, which is impractical for real-world deployment
- Reinforcement Learning (RL) alone fails in high-dimensional dexterous manipulation tasks due to sample inefficiency and exploration difficulties
- Rigidly transferring grasps (e.g., just copying wrist pose) often fails because new object shapes require different finger configurations to maintain functional contact
Concrete Example:
When transferring a grasp from a standard hammer to a mallet with a thicker handle, simply copying the joint angles or wrist position causes the fingers to clip through the object or fail to make contact. This method warps the hand configuration so the fingers wrap correctly around the thicker handle.
Key Novelty
Latent Space Non-Rigid Registration for Grasp Transfer
- Morphs a 'canonical' tool (with a known good grasp) to match the shape of a new, unseen tool using a deformation field learned from category-level variations
- Transfers the grasping contact points (keypoints) along this deformation field, then solves an inverse kinematics problem to find a feasible hand pose that matches these new contact points
- Uses this generalized grasp to initialize RL episodes (pre-grasp) and shape rewards, guiding the policy without forcing it to strictly mimic the demonstration
Architecture
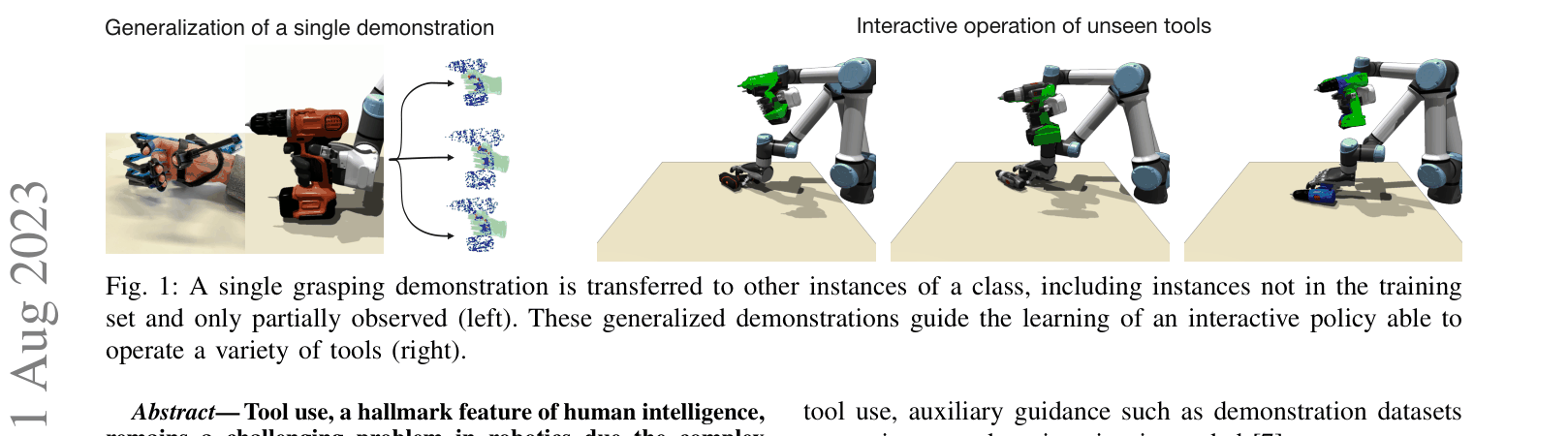
Conceptual overview of the system: Demonstration -> Generalization -> RL Policy.
Evaluation Highlights
- Achieved 96-97% success rate on 'Place mug' and 'Position drill' tasks using only one canonical demonstration per class
- Zero-shot generalization to unseen tools (not in training set) achieved 67% success on 'Place mug' using partial point-cloud inputs
- Proposed method reduces mean task-space error to ~0.7cm, significantly outperforming wrist-pose transfer (~2.5cm) and canonical grasp retention (~2.9cm)
Breakthrough Assessment
7/10
Strong contribution in combining geometric registration with RL for sample-efficient tool use. Successfully bridges the gap between rigid imitation and adaptive RL, though evaluation is limited to simulation.
