📝 Paper Summary
Benchmark datasets
Tool-use post-training
MetaTool is a benchmark and dataset designed to evaluate whether LLMs can accurately perceive the need for tools and select the correct ones from a library.
Core Problem
Existing benchmarks focus on how LLMs execute tool instructions, neglecting the critical upstream decisions of whether to use a tool (awareness) and which tool to select.
Why it matters:
- In agent scenarios (e.g., AutoGPT), LLMs must autonomously decide when to resort to external tools, a step prone to hallucination if capability boundaries are unclear
- Overlapping tool functionalities in real-world libraries confuse models, leading to unreliable or inefficient tool selection
- Current evaluations lack diverse user query types (e.g., emotional or implicit requests), failing to cover realistic usage scenarios
Concrete Example:
When a user asks a question an LLM can solve internally (e.g., common sense), the model might unnecessarily invoke a tool. Conversely, when faced with non-existent tools in a list, models often hallucinate a selection rather than abstaining.
Key Novelty
MetaTool Benchmark & ToolE Dataset
- Introduction of the ToolE dataset containing 21,127 queries generated via diverse prompting strategies (emotional, keyword-based, detail-oriented) to simulate varied user behaviors
- A rigorous tool selection evaluation framework covering four distinct sub-tasks: similar choices, specific scenarios (e.g., finance), reliability (hallucination checks), and multi-tool inference
Architecture
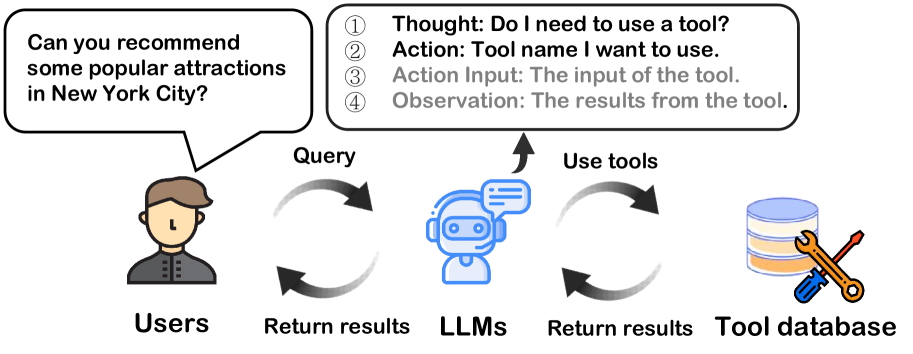
The typical process of an LLM using tools, divided into four stages
Breakthrough Assessment
7/10
Addresses a critical gap in agentic AI (decision-making vs. execution). The focus on negative constraints (when NOT to use tools) and reliability is valuable, though the methodology is primarily benchmarking existing models.