📝 Paper Summary
Multi-call tool use with fixed plan
Tool profiling
ToolScope improves LLM agent tool selection by automatically merging redundant tools into a unified graph and using a hybrid retrieval-reranking pipeline to filter irrelevant options.
Core Problem
Large toolsets often contain tools with overlapping names and descriptions (redundancy) and exceed LLM context limits, causing agents to select incorrect tools or fail to process the input.
Why it matters:
- Ambiguous or duplicate tool definitions confuse retrievers and LLMs, leading to lower selection accuracy
- Strict input context limits prevent agents from considering large numbers of tools, forcing aggressive filtering that may discard the correct tool
- Existing methods improve individual tool documentation but fail to address cross-tool semantic overlap or simultaneously solve context limitations
Concrete Example:
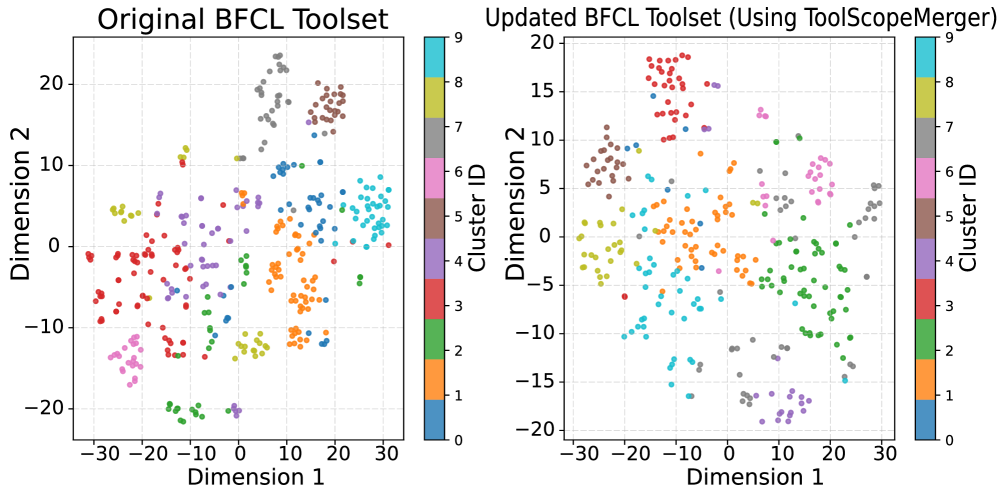
In a dataset like Seal-Tools, multiple tools might perform 'weather checking' with slightly different names. An agent might hallucinate or pick the wrong variant due to ambiguity. ToolScope merges these into one canonical tool entry.
Key Novelty
Automated Tool Graph Merging & Hybrid Context-Aware Retrieval
- Constructs a tool graph where nodes are tools and edges represent semantic equivalence, then collapses connected components into single canonical tools to remove redundancy
- Uses an LLM-based 'Auto-Correction' step to audit merge decisions, splitting clusters if they contain non-equivalent tools
- Employs a hybrid retrieval strategy (sparse + dense) followed by a cross-encoder reranker to select only the top-k relevant tools, drastically compressing the context window
Architecture
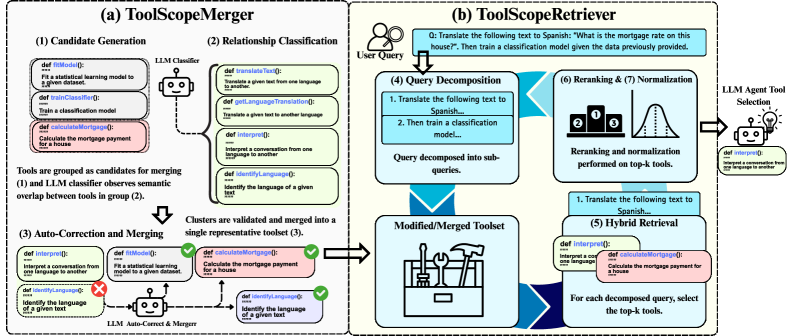
The complete ToolScope pipeline including the offline Merger process and the online Retriever process.
Evaluation Highlights
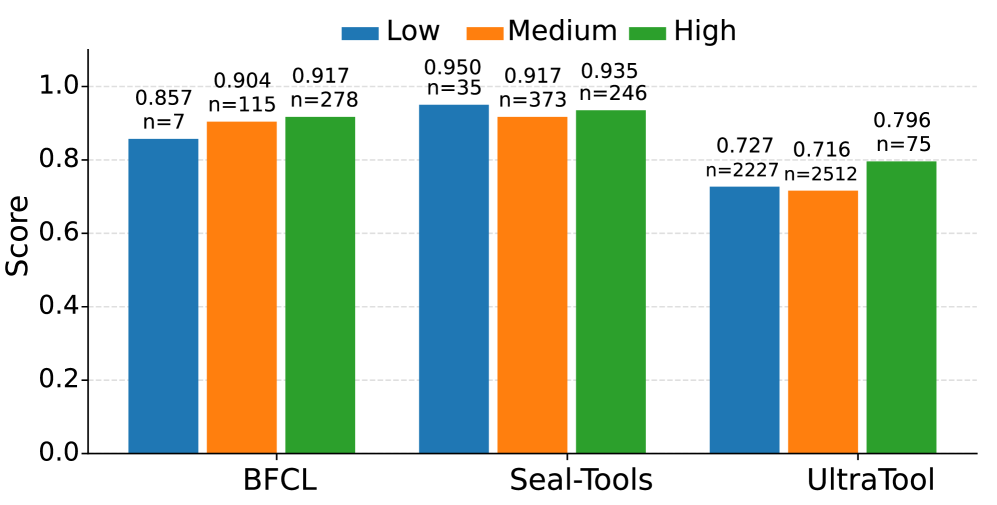
- +34.6% improvement in Correct Selection Rate (CSR) on Seal-Tools (a challenging multi-tool benchmark) using GPT-4o compared to baselines
- +38.6% improvement in CSR on UltraTool using GPT-4o, demonstrating effectiveness in real-world scenarios
- Reduces context length by 99.9% on Seal-Tools (from ~292k tokens to ~300 tokens) while maintaining high retrieval recall
Breakthrough Assessment
7/10
Strong empirical gains on difficult benchmarks and a practical solution to the 'too many tools' problem. The automated merging with LLM correction is a clever addition to standard retrieval pipelines.