📝 Paper Summary
Tool profiling
Tool-use post-training
Trace-Free+ uses curriculum learning to train a tool description generator that transfers insights from trace-rich training scenarios to trace-free inference settings, enabling better tool use without requiring trial-and-error interactions.
Core Problem
Tool interfaces (descriptions and schemas) are designed for humans, not LLMs, leading to failures in tool selection and parameter generation. Existing optimization methods rely on execution traces (trial loops), which are unavailable in cold-start or privacy-constrained deployments.
Why it matters:
- LLM agents often fail when selecting from large tool sets because documentation is ambiguous or missing critical usage constraints
- Interacting with tools to collect traces (e.g., 'try and fail') is often unsafe, costly (API fees), or impossible for new private tools
- Existing prompt-based optimization is slow and does not generalize to unseen tools
Concrete Example:
A tool parameter 'ip_address' might require strictly IPv4 format, but the original description doesn't state this. An agent fails repeatedly trying IPv6. Trace-based methods fix this by observing the failure, but Trace-Free+ learns to predict such constraints proactively without needing the initial failure.
Key Novelty
Curriculum Learning for Trace-Free Tool Interface Improvement
- Trains a model to rewrite tool descriptions by progressively removing access to execution traces during training
- Uses an agentic workflow to synthesize a large-scale dataset of high-quality tool descriptions grounded in real execution failures, then distills this knowledge into a generator
- Enables 'zero-shot' optimization of documentation for new tools without requiring any API calls
Architecture
Conceptual workflow of Trace-Free+: From data synthesis (using traces to fix docs) to curriculum training (gradually hiding traces) to trace-free inference.
Evaluation Highlights
- +7.1% success rate on StableToolBench (unseen tools) compared to the original tool descriptions using Llama-3-8B
- Achieves performance comparable to trace-based upper bounds while using zero traces at inference time
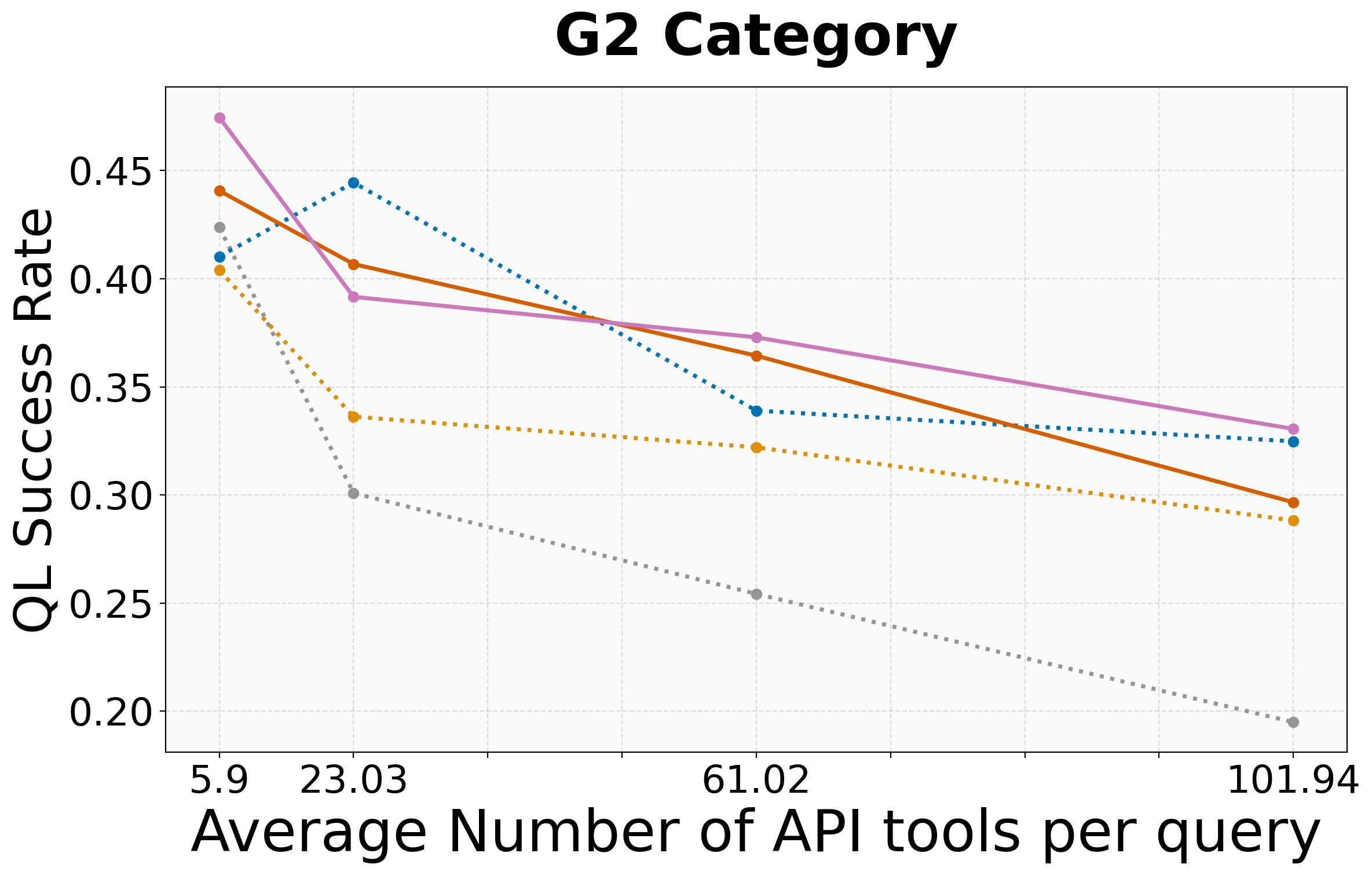
- Robust to scaling: maintains performance even as the number of candidate tools increases to 100, whereas baselines degrade significantly
Breakthrough Assessment
7/10
Offers a practical solution to the 'cold start' problem in tool use. While the gain is moderate (+7%), the ability to optimize documentation without execution access is a significant deployment enabler.