📊 Experiments & Results
Evaluation Setup
Retrieve relevant tools from a corpus of 43,215 tools given a user query.
Benchmarks:
- ToolRet (Tool Retrieval) [New]
Metrics:
- nDCG@10
- Recall@10
- Pass Rate (End-to-End)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| ToolRet | nDCG@10 | 33.83 | 33.83 | 0.00 |
| ToolRet | nDCG@10 | 26.96 | 26.96 | 0.00 |
| Fine-tuning on ToolRet-train significantly improves performance of smaller models over their zero-shot baselines. | ||||
| ToolRet | nDCG@10 | 25.84 | 68.60 | +42.76 |
| ToolRet | Recall@5 | 34.50 | 80.62 | +46.12 |
Experiment Figures
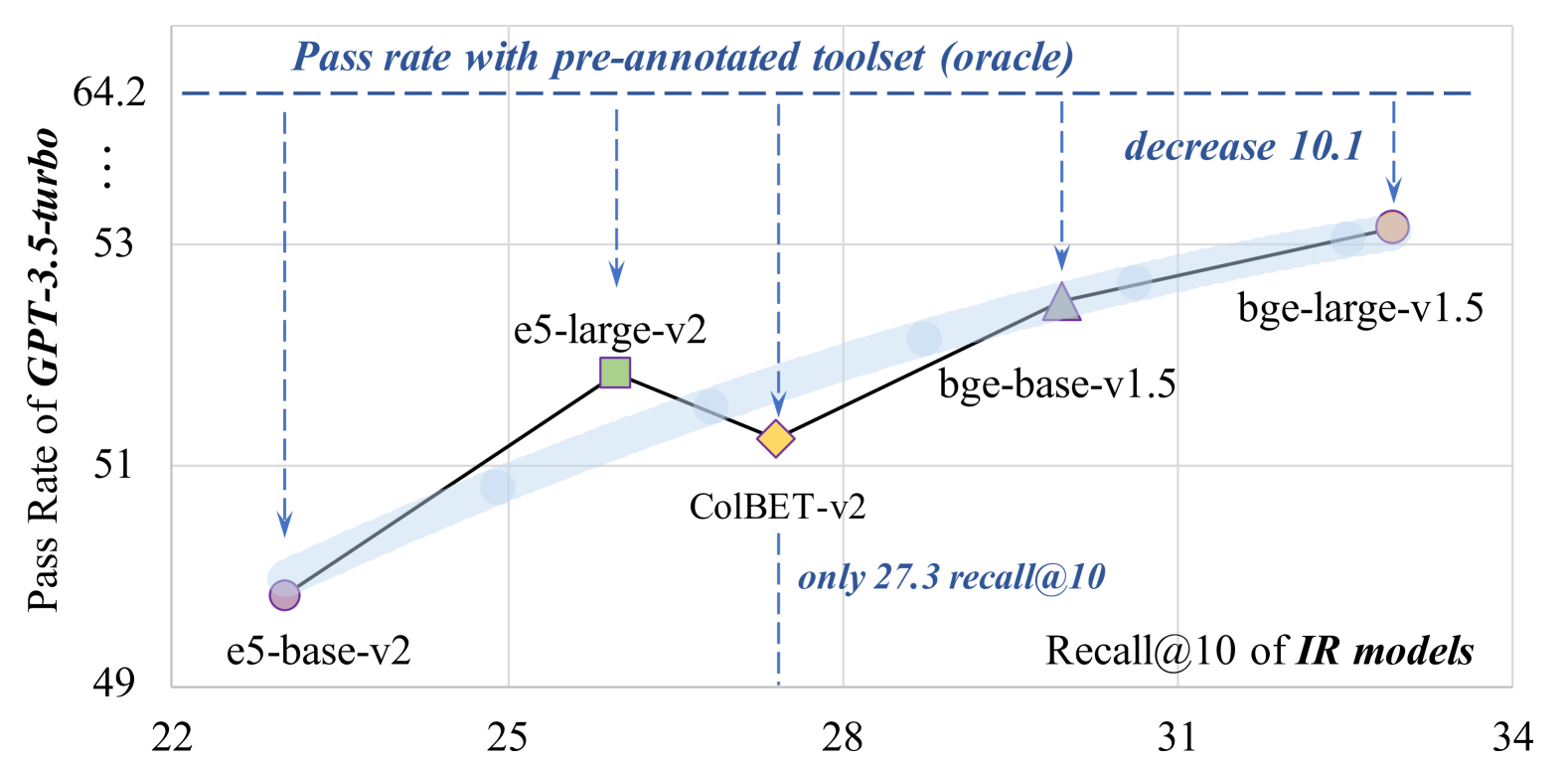
Pilot experiment results on ToolBench showing the impact of retrieval on agent performance
Main Takeaways
- Conventional IR models, even powerful ones like NV-embed-v1, are not 'tool-savvy' zero-shot, struggling with the specific semantics of tool retrieval (low term overlap).
- Fine-tuning on the proposed ToolRet-train dataset yields massive improvements (e.g., ~40 point jump in nDCG), demonstrating the necessity of domain-specific training data.
- Low retrieval quality is a confirmed bottleneck: pilot experiments showed agent success rates drop significantly when using retrieved tools vs. ground truth tools.
- The benchmark is heterogeneous, covering web APIs, code functions, and customized apps, ensuring models are tested across diverse tool types.