📝 Paper Summary
Agentic RAG pipeline
Reinforcement Learning for RAG
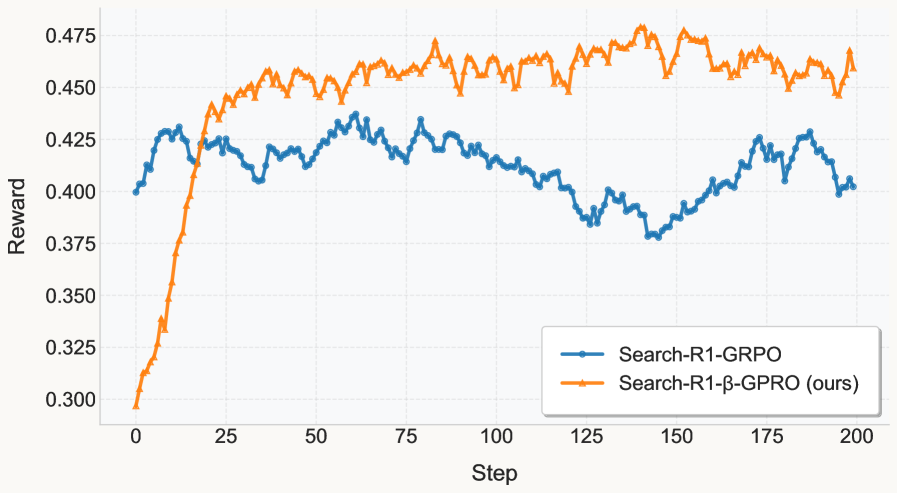
Beta-GRPO improves Agentic RAG efficiency by modifying the reinforcement learning reward to only incentivize search actions when the model is confident in its query generation, thereby aligning search behavior with knowledge boundaries.
Core Problem
Current Agentic RAG systems suffer from sub-optimal behaviors: 'over-search' (retrieving information the model already knows) and 'under-search' (hallucinating instead of retrieving necessary information).
Why it matters:
- Inefficient searching wastes computational resources and increases latency without improving answer quality
- Failing to search when necessary leads to factual errors and hallucinations, degrading system reliability
- Existing RL methods reward final correctness but do not explicitly penalize the model for being unsure about its own knowledge boundaries
Concrete Example:
For the simple question 'Who was the first president?', a baseline model unnecessarily initiates a search (over-search). Conversely, for an obscure question like 'In what Country is Sul America Esporte Clube in?', the baseline hallucinates an answer (under-search), whereas the proposed model correctly identifies the knowledge gap and searches.
Key Novelty
Beta-GRPO (Confidence-Aware Group Relative Policy Optimization)
- Uses the minimum token probability within a generated search query as a proxy for the model's 'confidence' in that search action
- Modifies the RL reward function to grant rewards only if the model is both correct AND its search confidence exceeds a threshold (beta)
- Forces the agent to learn to search only when it can formulate a high-certainty query, effectively calibrating its knowledge boundaries
Architecture
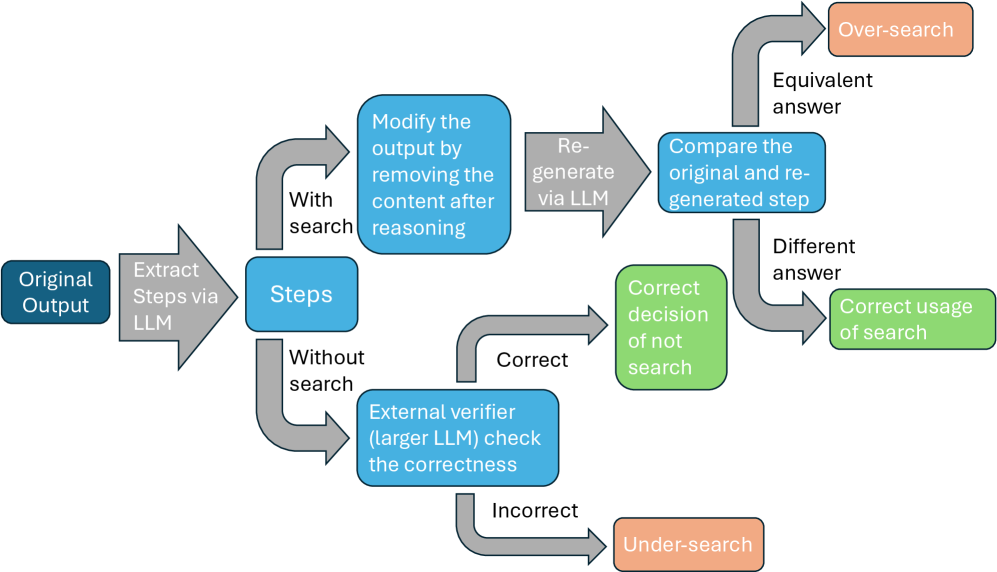
Analysis pipeline for identifying over-search and under-search behaviors in agentic trajectories
Evaluation Highlights
- Achieves 50.55% Average Exact Match (EM) across 7 QA benchmarks, outperforming the base Search-R1-GRPO (48.62%) and R1-Searcher (45.31%)
- Reduces under-search rate by ~7.3% (from 42.04% to 34.71%) compared to the Search-R1-GRPO baseline
- Reduces over-search rate by ~1.2% (from 21.10% to 19.89%), demonstrating better efficiency in utilizing internal knowledge
Breakthrough Assessment
7/10
Identifies and quantifies a critical efficiency problem in Agentic RAG (over/under-search) and provides a simple, effective RL-based solution. The gains are consistent, though the method is a modification of existing GRPO rather than a new architecture.