📝 Paper Summary
Automated workflow generation
Robustness of LLM agents
RobustFlow improves the stability of automated agentic workflow generation by training models to produce structurally consistent plans for semantically equivalent queries using preference optimization.
Core Problem
Current agentic workflow generation methods are brittle; they produce wildly inconsistent structures when given semantically identical but differently phrased instructions.
Why it matters:
- Inconsistency undermines reliability and trustworthiness in real-world applications where users may phrase the same intent differently
- Existing methods show only 40-70% stability under semantic variations, even when LLM sampling temperature is zero
- Instability indicates a failure to achieve true semantic understanding rather than just random artifacts
Concrete Example:
When provided with a task description and then a paraphrased version of the same task, a standard generator might produce a linear chain for the first but a complex branching graph for the second, despite the underlying goal being identical.
Key Novelty
RobustFlow: Two-stage training for structural invariance
- Constructs 'semantic clusters' of synonymous task descriptions (via paraphrasing, noise injection) that should all map to the same canonical workflow structure
- Applies a 'score-first, vote-second' preference optimization where the most frequent and effective workflow structure in a cluster is treated as the positive training example, while divergent structures are negative examples
Architecture
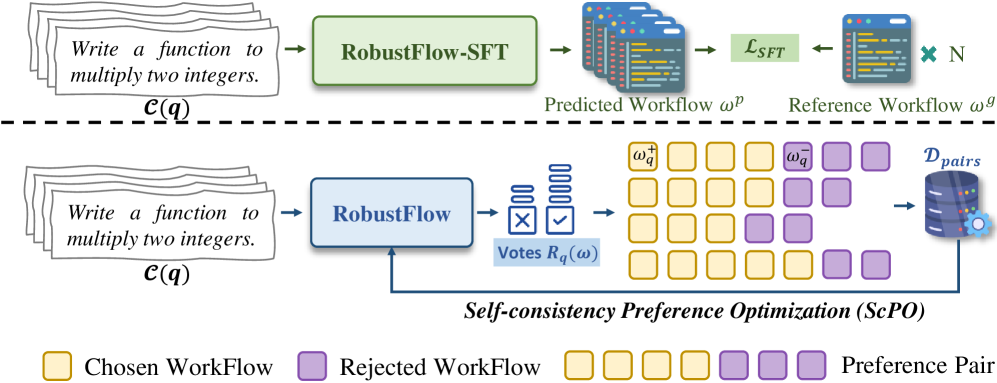
The two-stage training pipeline of RobustFlow: Instruction Augmented SFT followed by Self-Consistency Preference Optimization.
Evaluation Highlights
- Boosts workflow robustness scores to 70% - 90% across diverse domains, a substantial improvement over existing approaches
- Constructed a new dataset of 31,889 workflows generated from 1,255 task descriptions across 6 domains to benchmark robustness
- Demonstrates that instability persists even at zero temperature, confirming the need for specific robustness training rather than just reducing sampling randomness
Breakthrough Assessment
7/10
First quantitative analysis and dataset specifically targeting robustness in agentic workflow generation. The proposed preference optimization strategy effectively addresses the identified stability gap.