📝 Paper Summary
Agentic Memory
Multi-agent collaboration
Automated Feature Engineering
MAGS unifies feature selection and generation into a collaborative multi-agent system where a router plans optimization paths and agents improve via memory-augmented in-context learning.
Core Problem
Existing feature engineering methods perform selection and generation separately, failing to balance redundancy reduction with the creation of meaningful new dimensions.
Why it matters:
- Feature selection alone risks losing hidden interactions needed for predictive models by only filtering existing features
- Feature generation alone introduces redundancy and suboptimal dimensions without pruning
- Separate application of these techniques misses synergistic interactions, leading to suboptimal data representations in domains like predictive maintenance
Concrete Example:
In predictive maintenance, simply selecting sensor signals (vibration, temperature) misses complex health indicators (failure probability), while generating indicators without selection creates a bloated, noisy feature set.
Key Novelty
Multi-Agent System with Long and Short-Term Memory (MAGS)
- Models feature engineering as a teaming problem where a Router agent dynamically switches between a Selector (to prune) and a Generator (to expand) based on the current state
- treats feature sets as token sequences (postfix expressions) allowing LLM agents to manipulate them as language generation tasks
- Uses a dual-memory mechanism: Short-term memory for immediate trajectory refinement within an iteration, and Long-term memory to retrieve high-quality historical demonstrations
Architecture
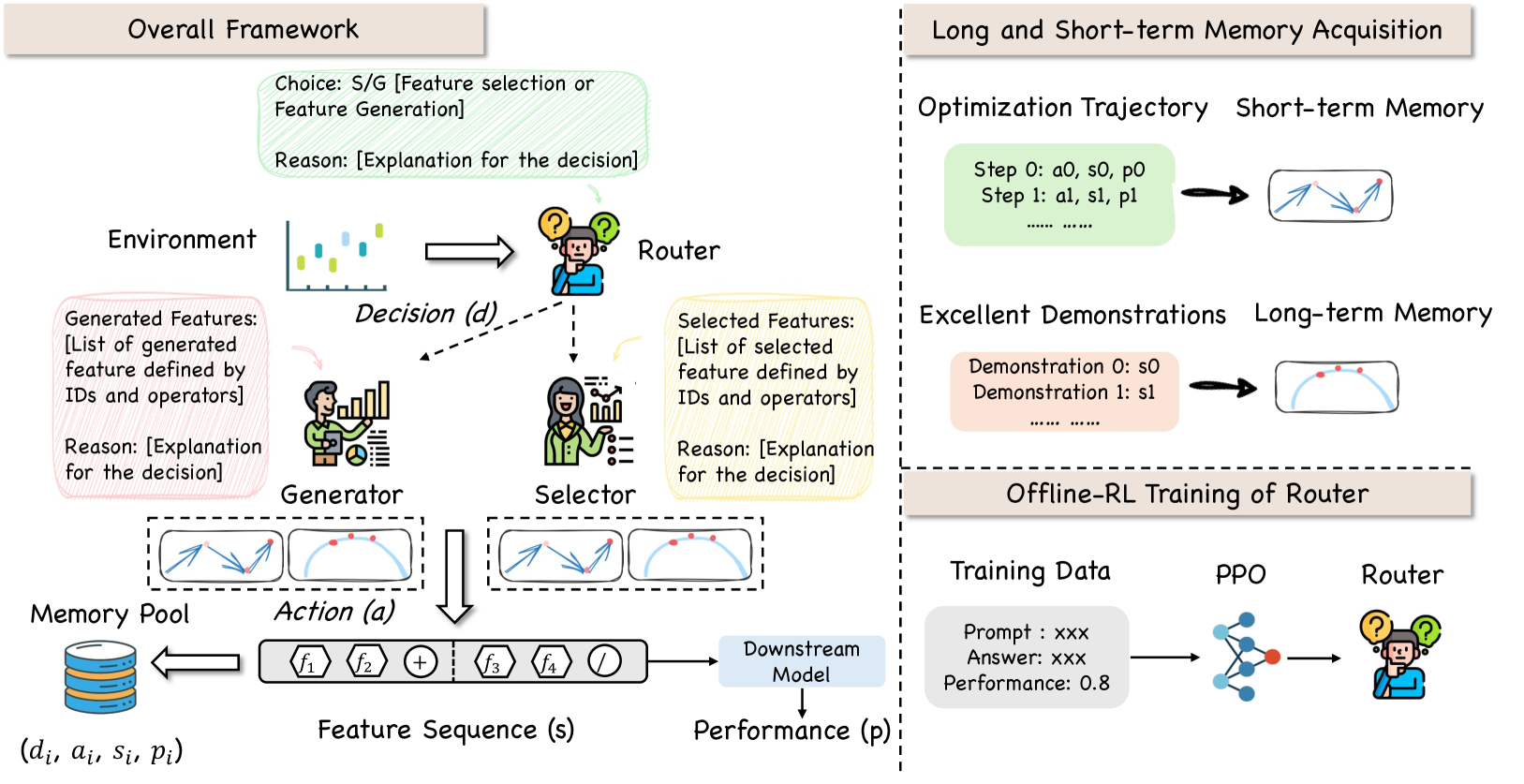
The three technical components of MAGS: the agentic teaming framework, the dual memory mechanism, and the offline RL module.
Breakthrough Assessment
7/10
Novel framing of feature engineering as an agentic planning problem with distinct router/selector/generator roles. The dual-memory integration is logically sound. Score limited by lack of visible quantitative results in the provided text.