📝 Paper Summary
Software Testing
Agentic AI
TestGenAgent iteratively refines zero-shot generated test suites using execution logs and coverage reports to produce high-quality, readable unit tests at low cost.
Core Problem
Existing automated testing tools are either unreadable (search-based) or prone to hallucinations and lack of context (LLM-based), while current agentic approaches are prohibitively expensive.
Why it matters:
- Manual test creation is costly and often neglected, leading to buggy software
- Search-based tools like EvoSuite generate code that developers find difficult to maintain or debug
- Prior agentic methods operate at the method level, costing over $2.00 per file, which prevents scaling to large repositories
Concrete Example:
In `pydata/xarray`, GPT-4o generates a test that fails due to a timestamp `AttributeError`. TestGenAgent reads the error log, fixes the bug, sees `_round` method is uncovered in the coverage report, and adds a targeted test.
Key Novelty
Iterative Feedback-Driven Refinement at File Level
- Starts with a zero-shot LLM-generated test suite rather than starting from scratch, using it as a high-quality template
- Feeds full coverage reports and execution error logs back to the agent, allowing it to plan fixes and target specific uncovered lines
- Operates at the file level (testing all methods in a file at once) rather than per-method, significantly reducing token costs
Architecture
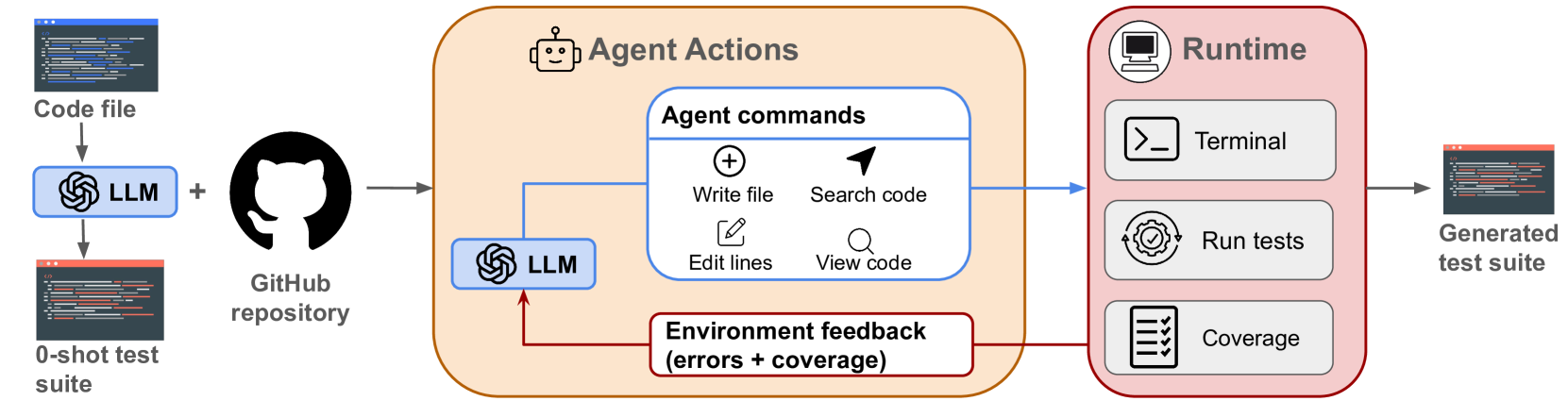
The workflow of TestGenAgent, illustrating the cycle between agent actions and the execution environment.
Evaluation Highlights
- Achieves 84.3% Pass@1 rate on the TestGenEval benchmark, setting a new record for automated test generation
- Improves mutation score (ability to catch bugs) by 15.4 percentage points over the one-iteration LLM baseline
- Reduces cost to $0.63 per file, substantially cheaper than prior agentic methods that cost over $2.00 per file
Breakthrough Assessment
8/10
Significantly improves practical usability of automated testing by combining high coverage with readability and low cost. The shift to file-level processing and iterative refinement addresses key scalability bottlenecks.