📝 Paper Summary
Synthetic Data Generation
Agentic Workflows
AgentInstruct is an agentic framework that generates massive amounts of diverse, high-quality post-training data from raw documents by using flows of suggester-editor agents to iteratively refine instructions.
Core Problem
Existing synthetic data methods often rely on limited seed prompts or simple model imitation, leading to low diversity, potential model collapse, and failure to teach complex capabilities.
Why it matters:
- Pre-training on synthetic data from other models can cause model degeneration (model collapse)
- Standard post-training often teaches stylistic mimicry rather than genuine reasoning capabilities
- Creating high-quality, diverse synthetic data usually requires expensive human curation
Concrete Example:
A standard synthetic data generator might take a document and ask a simple question like 'Summarize this'. AgentInstruct transforms the text into a debate format, then generates a 'Strengthen the argument' question, then refines it to add a difficult distractor, creating a much harder reasoning task.
Key Novelty
Generative Teaching via Agentic Flows
- Uses raw documents (not existing prompts) as seeds to ensure diversity and avoid benchmark contamination
- Employes a three-stage pipeline: Content Transformation (e.g., turning text into a debate), Seed Instruction Generation (creating tasks), and Instruction Refinement (Suggester-Editor agents making tasks harder)
- Leverages agentic capabilities like reflection, tool use, and multi-turn iteration to generate data that exceeds the teacher model's raw zero-shot quality
Architecture
Conceptual flow of the AgentInstruct data generation pipeline
Evaluation Highlights
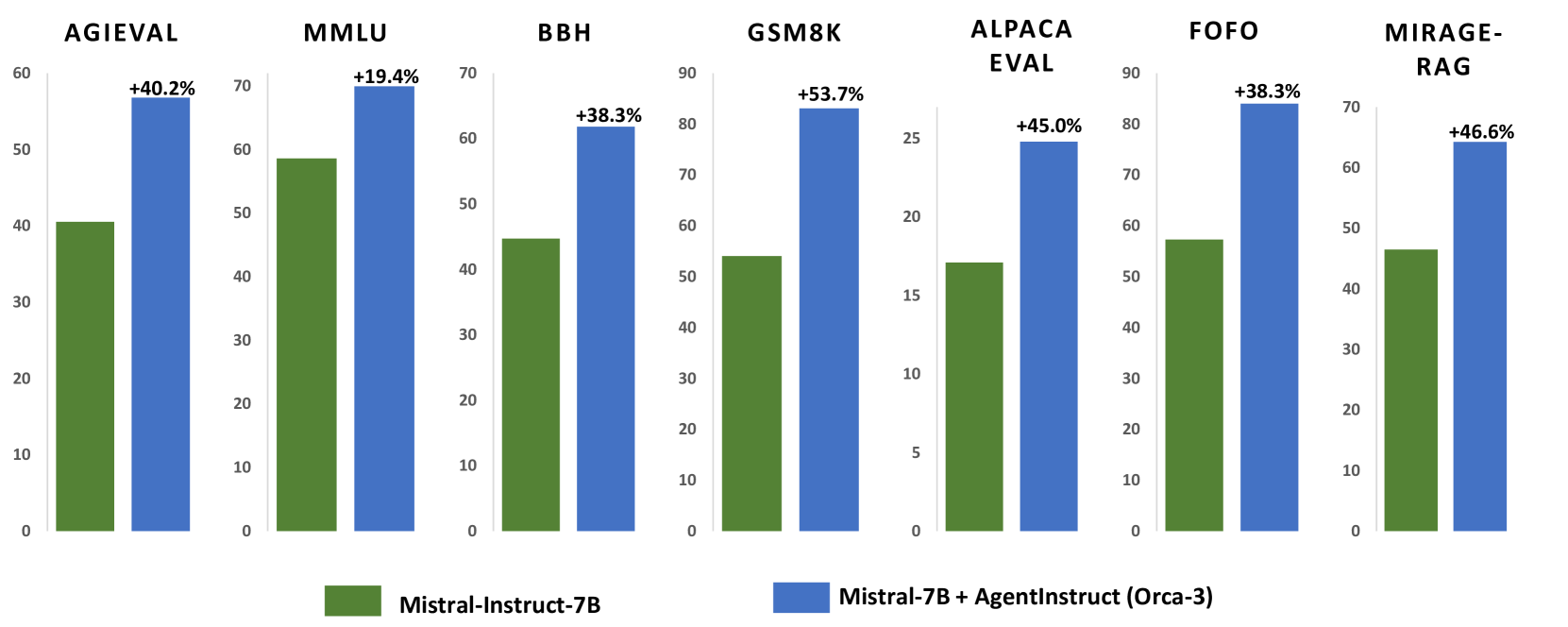
- +40% improvement on AGIEval and +54% on GSM8K for Orca-3 (Mistral-7b finetuned on AgentInstruct data) compared to Mistral-7b-Instruct
- +19% improvement on MMLU and +38% on BBH compared to Mistral-7b-Instruct
- 31.34% reduction in hallucination rates across multiple summarization benchmarks compared to Mistral-7b-Instruct
Breakthrough Assessment
9/10
Demonstrates massive improvements (40-50%) over strong baselines using purely synthetic data generated from raw text, effectively solving the diversity/quality bottleneck in synthetic data generation.