📝 Paper Summary
Agentic Systems
Tool-Integrated Reasoning
Reinforcement Learning for Agents
AgentFlow is a trainable agentic framework that optimizes a planner module directly inside the multi-turn execution loop using Flow-GRPO, converting long-horizon sparse rewards into tractable single-turn updates.
Core Problem
Existing tool-augmented approaches either train monolithic policies that scale poorly to long horizons or rely on frozen, training-free agentic systems that struggle with coordination and sparse rewards.
Why it matters:
- Monolithic models suffer from stability issues as horizons lengthen and tool diversity grows
- Training-free agentic systems rely on brittle handcrafted logic that cannot adapt to dynamic environments or recover from errors
- Offline training methods (SFT/DPO) decouple optimization from live system dynamics, leading to poor adaptation
Concrete Example:
In a long-horizon search task, a monolithic model might hallucinate after a failed tool call, while a training-free agent might get stuck in a loop. AgentFlow's trained planner learns to recognize the failure from the verifier's signal and pivot its strategy in the next turn.
Key Novelty
In-the-Flow Optimization for Agentic Planners
- Embeds the optimization process directly within the live, multi-turn agent execution loop rather than training on static offline traces
- Decomposes the multi-turn RL problem into single-turn updates by broadcasting a final outcome reward to every step in the trajectory
- Uses a deterministic evolving memory to track state, ensuring transparency and enabling the planner to condition actions on the full history
Architecture
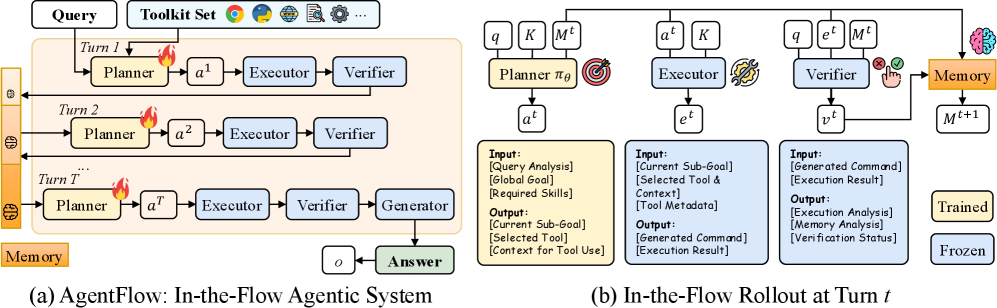
The AgentFlow framework illustrating the four modules (Planner, Executor, Verifier, Generator), the shared Memory, and the interactive loop.
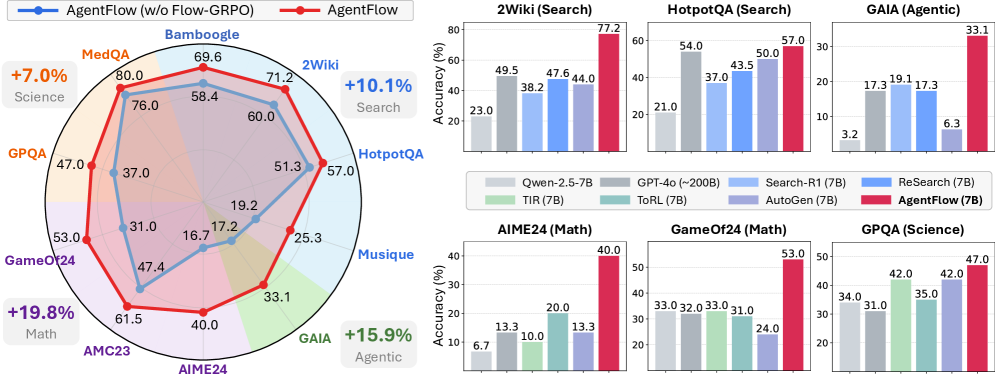
Evaluation Highlights
- +14.9% average accuracy gain on search tasks compared to top-performing baselines using a 7B backbone
- +14.5% improvement on mathematical reasoning benchmarks
- Surpasses the ~200B parameter GPT-4o across all tested domains (search, agentic, math, science) using only a 7B model
Breakthrough Assessment
9/10
Significant methodology shift from monolithic or frozen agents to on-policy modular training. The performance gains of a 7B model over GPT-4o on complex reasoning tasks are substantial.