📝 Paper Summary
Agentic Deep Research
Reinforcement Learning for Reasoning
Atom-Searcher optimizes agentic research by decomposing reasoning into functional "atomic thoughts" and applying a curriculum-based reinforcement learning strategy that transitions from fine-grained process supervision to outcome-based rewards.
Core Problem
Existing agentic deep research systems relying on outcome-based reinforcement learning suffer from gradient conflicts (where good reasoning is punished due to wrong final answers) and reward sparsity.
Why it matters:
- Current RAG workflows are too static for complex multi-hop reasoning, often failing to construct correct search paths.
- Outcome-based RL provides coarse feedback, penalizing entire trajectories even if intermediate steps were correct, which hinders the learning of effective research strategies.
- Sparse feedback requires larger datasets and longer training times to converge.
Concrete Example:
In a standard RL setup, if an agent performs an excellent search and synthesis but makes a minor error in the final calculation, the entire trajectory is penalized. This discourages the agent from repeating the actually effective search strategy it used.
Key Novelty
Atomic Thought & Curriculum-Based Reward Aggregation
- Decomposes the `<think>` process into fine-grained functional units called 'Atomic Thoughts' (e.g., Reflection, Verification), scored individually by a Reasoning Reward Model (RRM).
- Uses a time-dependent mixing strategy for rewards: heavily weights fine-grained process rewards (Atomic Thought Reward) early in training to guide exploration, then linearly decays to prioritize outcome rewards (F1 score) to reduce noise and ensure accuracy.
Architecture
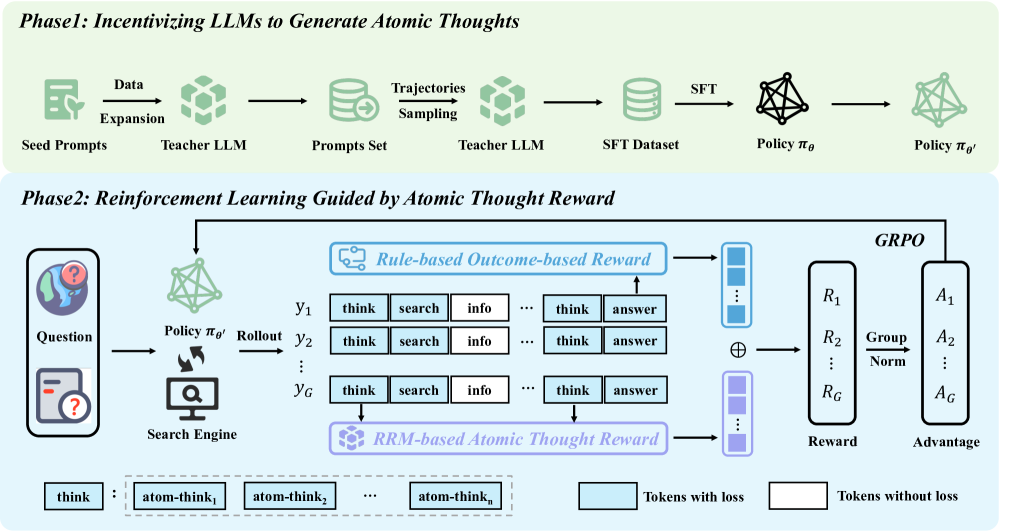
The two-phase training framework of Atom-Searcher.
Breakthrough Assessment
8/10
Addresses the critical 'black box' reasoning problem in agents by formalizing atomic thoughts and solving the gradient conflict issue in RL. The curriculum-based reward weighting is a logically sound and practical contribution.