📝 Paper Summary
Multi-turn w. user interactions
Tool-use post-training
CoALM is a unified model family trained on a novel dataset merging multi-turn dialogue, tool use, and ReAct reasoning to master both conversational and agentic tasks simultaneously.
Core Problem
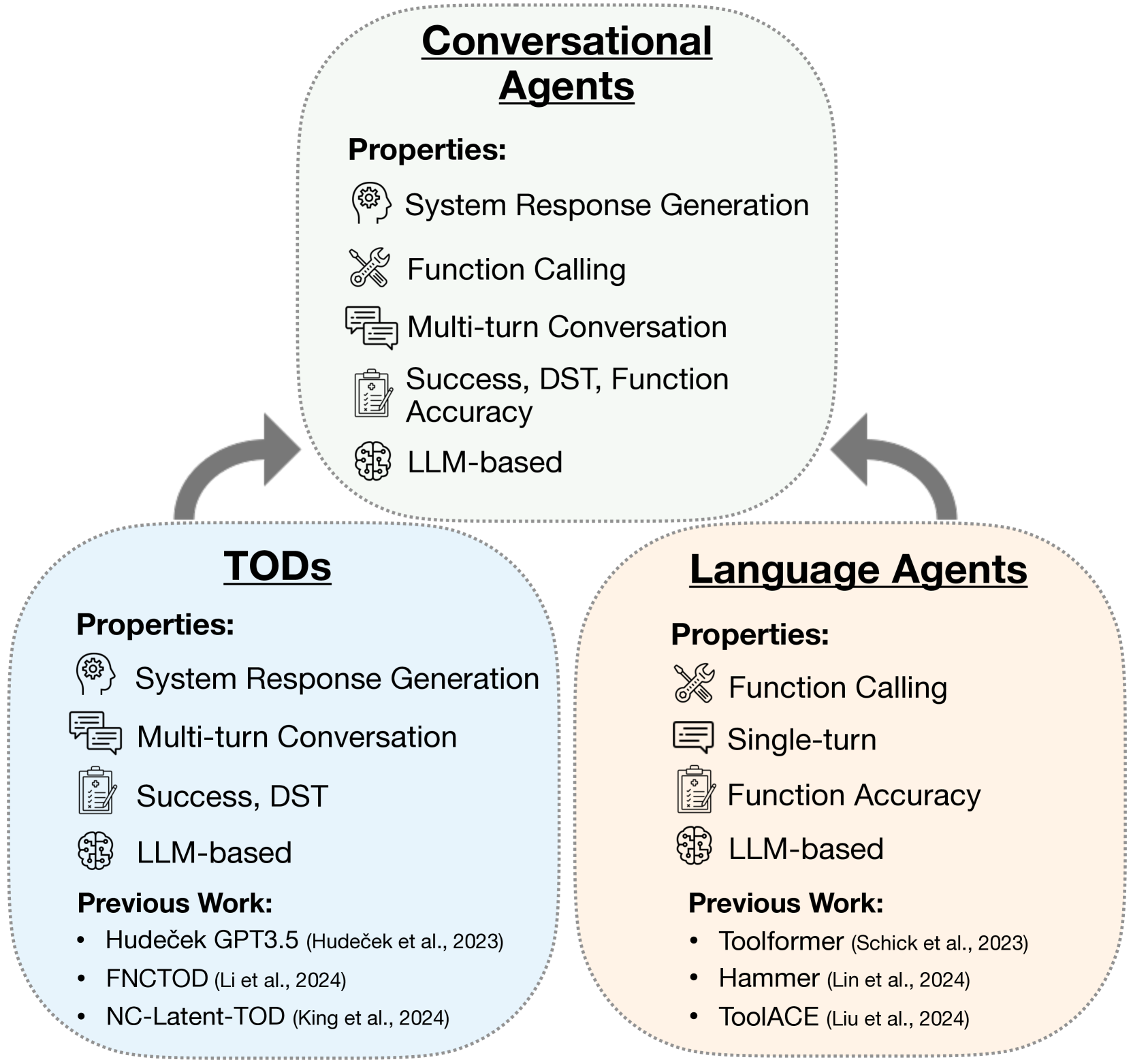
Existing models specialize in either task-oriented dialogue (TOD) or tool calling (Language Agents), failing to generalize; TOD systems lack diverse API support, while agents struggle with multi-turn intent tracking.
Why it matters:
- Users require agents that can both clarify ambiguous intent through conversation and execute complex actions via diverse APIs
- Current approaches require expensive fine-tuning or brittle prompt engineering to adapt to new services
- A significant performance gap exists between open-source models and proprietary models like GPT-4 on integrated conversational tasks
Concrete Example:
When a user says 'Find me a hotel', a pure tool-use agent might fail to ask clarifying questions (location, price) and just call a generic API, while a traditional dialogue system can ask questions but cannot call new, unseen APIs like 'search_direct_flight' without retraining.
Key Novelty
Unified Conversational Agentic Language Model (CoALM)
- Creates CoALM-IT, a dataset interleaving three skills: dialogue state tracking (TOD), complex function calling (LA), and a novel Conversational ReAct (CRA) format
- CRA introduces multi-step 'thought' processes into multi-turn dialogue: one thought for deciding API calls and another for formulating user responses
- Trains a single model family to handle both state tracking and dynamic API usage without switching models or pipelines
Architecture
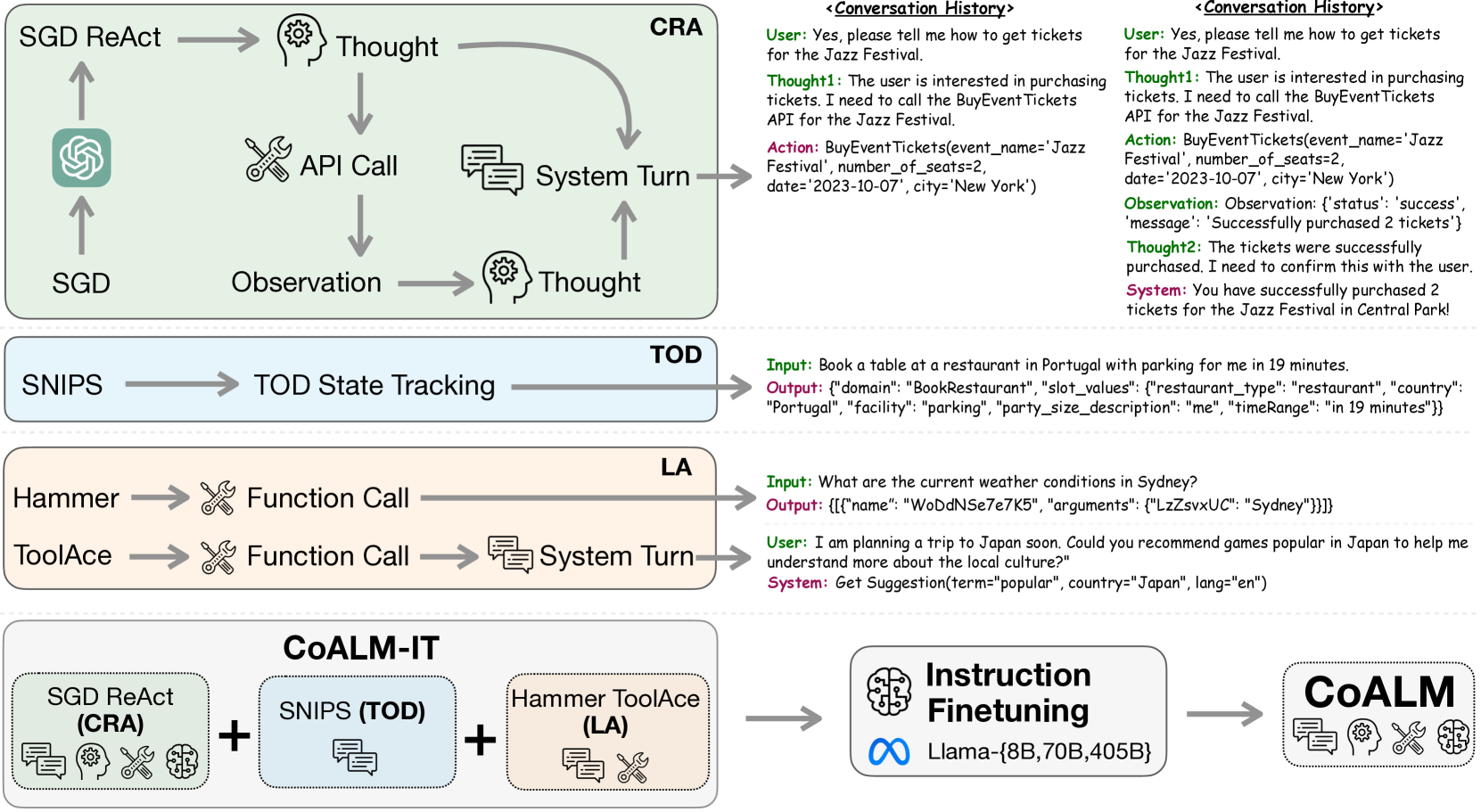
The CoALM training pipeline, showing the three data sources (TOD, LA, CRA) merging into the CoALM-IT dataset for multi-task fine-tuning.
Evaluation Highlights
- CoALM-70B achieves +2.2% success rate over GPT-4o on MultiWOZ 2.4 (TOD benchmark) while maintaining strong function calling capabilities
- On BFCL V3 (function calling), CoALM-70B outperforms GPT-4o with an accuracy of 80.50% vs 78.43%
- CoALM-8B outperforms the specialized ToolAce-8B model by +12.5% on MultiWOZ Success Rate, showing superior multi-turn management
Breakthrough Assessment
8/10
Successfully bridges the gap between dialogue systems and agentic tool-use models with a unified open-source approach that beats GPT-4o on key benchmarks.