📝 Paper Summary
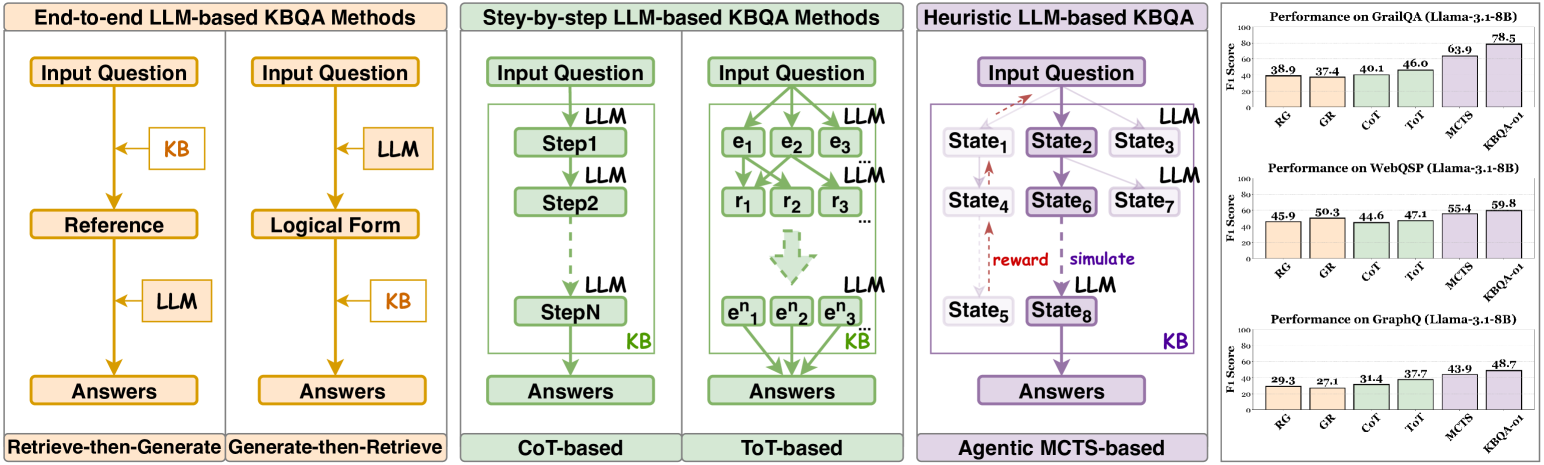
Knowledge Base Question Answering (KBQA)
Agentic reasoning
Low-resource learning
KBQA-o1 combines a ReAct-based agent for KB exploration with Monte Carlo Tree Search to generate high-quality logical forms, refining itself via incremental fine-tuning on self-generated data.
Core Problem
Existing KBQA methods struggle with weak awareness of the Knowledge Base environment (hallucinating schemas) and get stuck in local optima during step-by-step reasoning, while relying heavily on expensive human-annotated data.
Why it matters:
- End-to-end models often generate invalid relations or entities not present in the Knowledge Base due to lack of environment interaction
- Step-by-step methods (CoT/ToT) suffer from large search spaces or intermediate biases that lead to dead ends (local optima)
- Annotating logical forms for large-scale Knowledge Bases is prohibitively expensive, limiting performance in low-resource scenarios
Concrete Example:
When asking a multi-hop question, an end-to-end model might generate a relation like 'film.actor' when the KB schema actually requires 'film.film.actor'. A standard CoT agent might select the first plausible relation it sees and get stuck, unable to backtrack when that path yields no answer.
Key Novelty
Agentic MCTS with Incremental Self-Training
- Treats logical form generation as a sequential decision process where an agent interacts with the KB (using tools like 'find_relation') to validate every step against actual KB schema
- Uses MCTS guided by a policy model (for lookahead) and a reward model (for evaluation) to navigate the huge search space of relations, avoiding local optima by exploring multiple reasoning paths
- Eliminates the need for massive human annotation by using the MCTS agent to generate successful trajectories on unlabeled questions, then fine-tuning the models on these high-quality 'silver' traces
Architecture
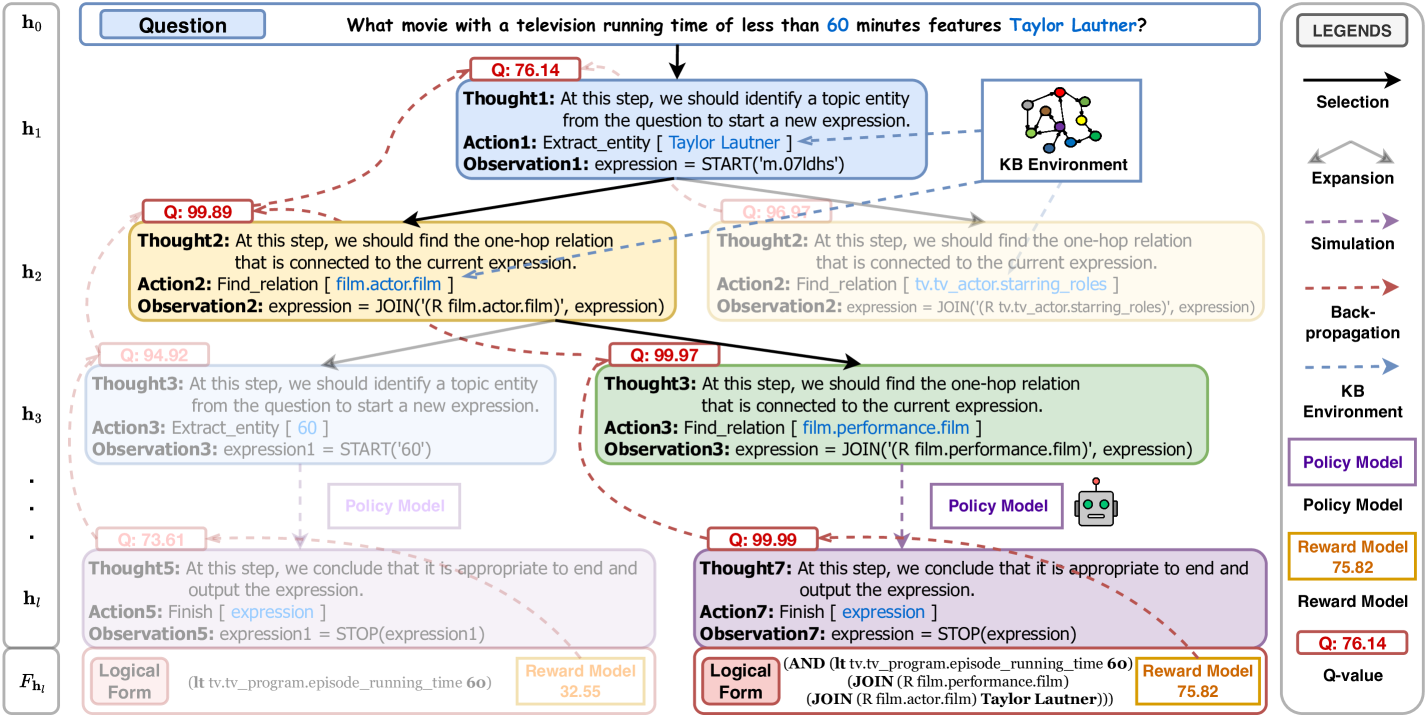
The MCTS-based agent exploration process. It illustrates the four stages: Selection, Expansion, Simulation, and Back-propagation.
Evaluation Highlights
- Boosts Llama-3.1-8B F1 performance on GrailQA to 78.5% in low-resource settings, compared to 48.5% for the previous SOTA method (KB-BINDER) with GPT-3.5
- Achieves 78.0% F1 on WebQSP using only 5% of training data, surpassing full-data supervised baselines like PIGNET (71.3%)
- Outperforms GPT-4 (CoT) on GrailQA (78.5% vs 64.9%) despite using a much smaller 8B parameter model
Breakthrough Assessment
8/10
Strong methodological contribution by successfully adapting MCTS to the KBQA structure generation problem and demonstrating massive gains in low-resource settings against much larger models.