📝 Paper Summary
Online Reinforcement Learning for LLM Agents
Multi-Turn Agent Interactions
Multi-Task Learning
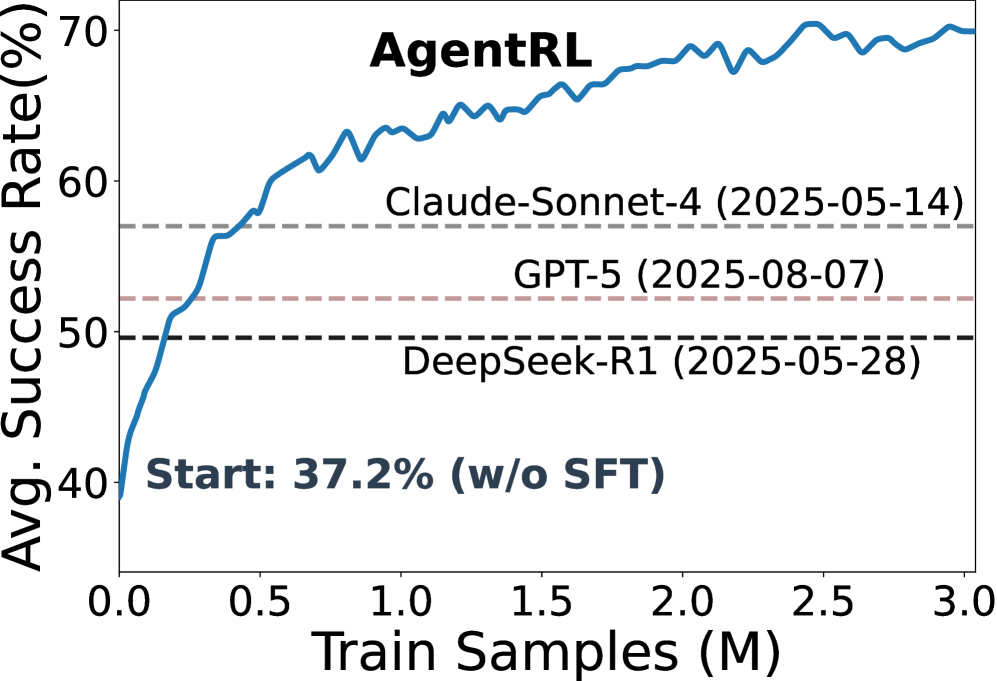
AgentRL provides a scalable infrastructure and stable algorithms for training LLM agents across multiple turns and tasks by decoupling generation from training and normalizing rewards.
Core Problem
Training LLM agents with RL in multi-turn, multi-task settings suffers from poor exploration, unstable optimization due to varying reward scales, and inefficient synchronous data collection.
Why it matters:
- Existing RL methods like PPO struggle with the sparse rewards and long horizons typical of agentic tasks
- Synchronous training pipelines leave GPUs idle while waiting for slow environment interactions, severely limiting throughput
- Multi-task training often fails because easier tasks with higher rewards dominate the gradient updates, causing the model to ignore harder tasks
Concrete Example:
In a web shopping task, an agent might need 10+ steps to checkout. Standard PPO might fail to explore the final 'purchase' action because it over-exploits early, easy steps. Meanwhile, if trained jointly with a simple search task, the high rewards from search overwhelm the learning signal from the complex shopping task.
Key Novelty
Asynchronous Generation-Training Pipeline with Cross-Policy Sampling
- Decouples inference (rollout) from learning (update) into separate asynchronous processes, maximizing GPU utilization unlike standard synchronous PPO
- Introduces cross-policy sampling: instead of sampling only from the current policy, it mixes samples from a pool of historical and external policies to improve exploration in sparse-reward settings
- Applies task advantage normalization to balance learning updates across different tasks with varying reward scales
Architecture
The AgentRL framework architecture showing the decoupled Actor-Learner structure.
Evaluation Highlights
- Outperforms GPT-4o on WebShop (success rate) using Llama-3-8B-Instruct trained with AgentRL
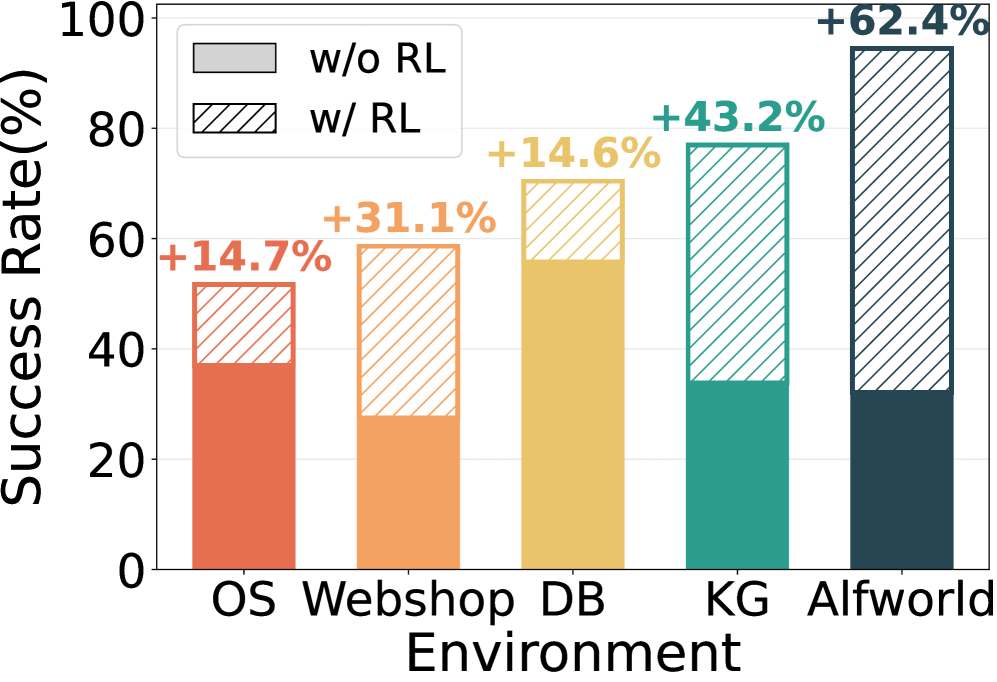
- +13.3% success rate improvement on OSWorld compared to PPO baseline
- Multi-task training matches the performance of task-specific experts (within margin of error) while using a single shared model
Breakthrough Assessment
8/10
Significant contribution to infrastructure and stability for online RL, addressing the key bottleneck of throughput in agent training. Adopted by AutoGLM.