📝 Paper Summary
Long-form video understanding
Multimodal agents
Deep Video Discovery (DVD) treats long-form video understanding as a multi-step search problem, using an LLM agent to iteratively query a multi-granular video database via specialized tools.
Core Problem
Current Large Language Models struggle with hour-long videos due to context length limits and information density, leading to poor reasoning and instruction following.
Why it matters:
- Existing video agents rely on rigid, manually designed workflows (e.g., tree searches) that cannot adapt to diverse query types
- Token compression techniques for long context handling introduce information loss and uncertainty
- Retrieving fine-grained details from hour-long content requires navigating both global context and pixel-level specifics, which fixed-structure methods fail to balance efficiently
Concrete Example:
Existing tree-based search methods navigate from root to leaf nodes, which is inefficient for fine-grained queries requiring direct leaf access. Furthermore, relevant entities might not be temporally close, making backdate mechanisms in tree searches inefficient.
Key Novelty
Autonomous Agentic Search over Multi-granular Video Database
- Conceptually reframes video understanding as an iterative 'search and discovery' process rather than a single-pass processing task
- Constructs a hierarchical database containing global summaries, clip-level captions, and raw frames
- Empowers an LLM agent with modular tools (Browse, Search, Inspect) to autonomously plan and execute search strategies based on the query's specific needs
Architecture
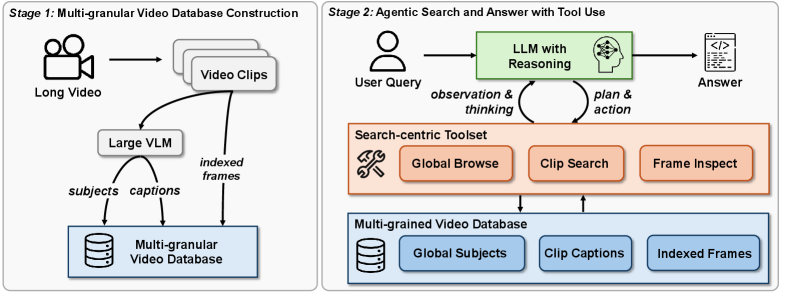
Overview of the Deep Video Discovery framework, showing the offline database construction (Left) and the online Agentic Search and Answer process (Right).
Evaluation Highlights
- Achieves 74.2% accuracy on the LVBench dataset, setting a new state-of-the-art
- Further improves LVBench accuracy to 76.0% when auxiliary transcripts are used
- Substantially surpasses all prior works on LVBench by a large margin
Breakthrough Assessment
8/10
Significant performance jump on a challenging benchmark (LVBench) by shifting from fixed processing pipelines to a fully agentic, search-based paradigm.