📝 Paper Summary
Vision-Language Models (VLMs)
Video Understanding
Molmo2 is a fully open-source family of vision-language models trained on 9 novel datasets to achieve state-of-the-art video understanding, pointing, and tracking without distilling proprietary models.
Core Problem
Strong video-language models remain proprietary, and open alternatives often rely on distilled data from closed models or lack crucial grounding capabilities like pointing and tracking in time.
Why it matters:
- Open-source community lacks foundational data and recipes to improve state-of-the-art video models without relying on proprietary distillation
- Downstream applications (robotics, sports analytics) need precise grounding—pointing to moments or tracking objects—which most current VLMs cannot do
- Existing open datasets are often short, lack density, or do not support complex temporal reasoning
Concrete Example:
A user asks 'How many times does the robot grasp the red block?'. A standard VLM answers '3 times' (text only). Molmo2 answers '3 times' and outputs specific temporal timestamps and spatial coordinates for each grasp event, enabling the user to jump to those exact moments.
Key Novelty
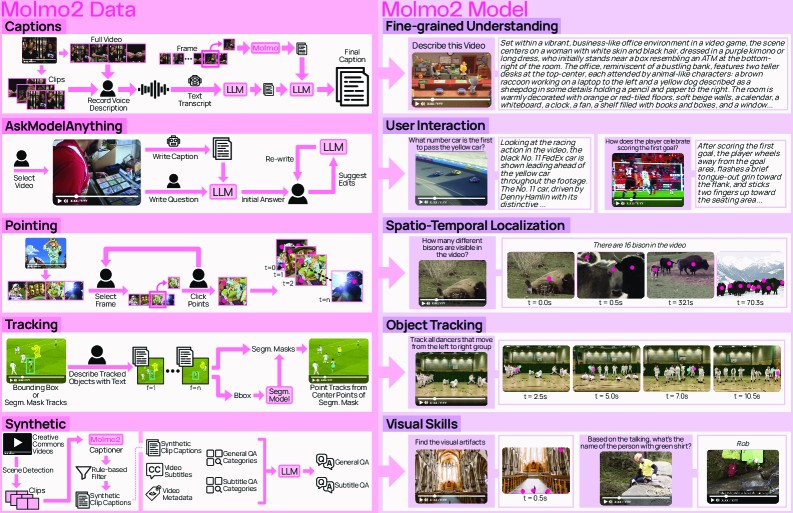
Fully Open Video Grounding & Understanding Pipeline (Molmo2)
- Introduces 9 new human-annotated and synthetic datasets built without proprietary model distillation, covering dense video captions, tracking, and pointing
- Extends 2D image pointing to the temporal domain, enabling models to output points for events in space and time (video pointing) and continuous object tracks
- Utilizes a training recipe with efficient sequence packing, message-tree encoding, and token-weighting to handle diverse inputs (images, multi-images, videos)
Architecture
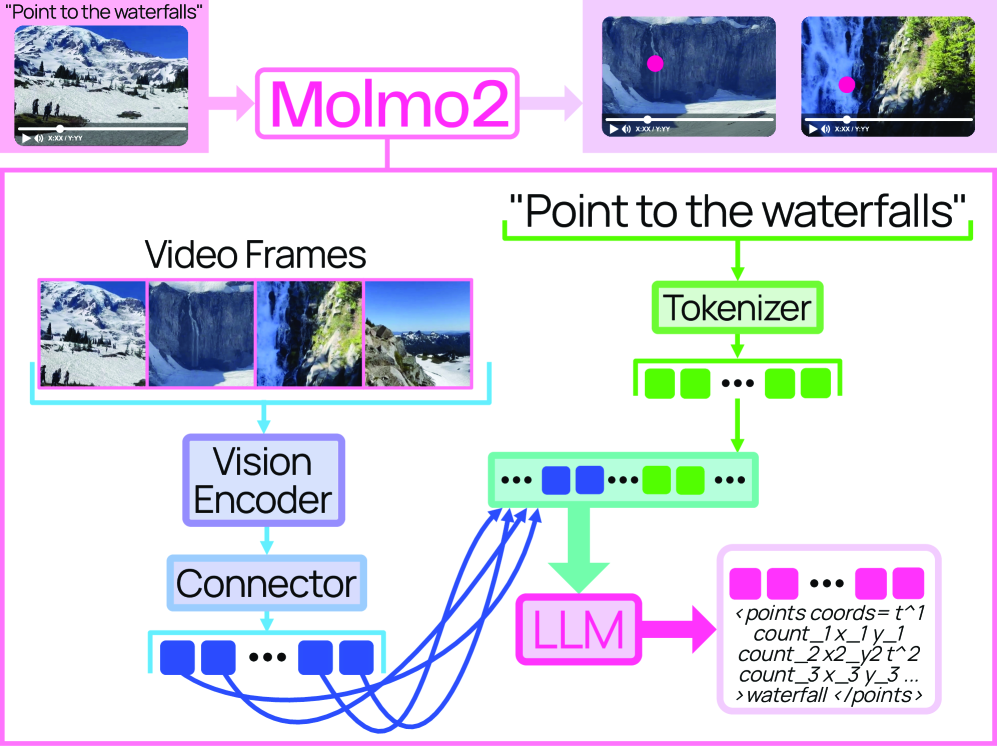
The Molmo2 architecture showing the connection between the Vision Encoder and LLM, specifically how video frames and point coordinates are handled.
Evaluation Highlights
- Outperforms Qwen3-VL on video counting (35.5 vs 29.6 accuracy) and matches proprietary models like Gemini 3 Pro on video pointing (38.4 vs 20.0 F1)
- Achieves best-in-class performance among open-weight models on short video benchmarks and captioning, with 86.2 average on short-video QA tasks
- Surpasses Gemini 2.5 Pro on tracking benchmarks (ReasonVOS: 78.8 vs 52.6 J&F) and sets new state-of-the-art for open models
Breakthrough Assessment
9/10
Significant contribution by releasing high-quality, non-distilled video grounding data and models that rival proprietary systems. The addition of temporal pointing/tracking to a generalist VLM is a major capability jump.