📝 Paper Summary
Agentic data analysis
Automated scientific discovery
Hypothesis testing
POPPER is an agentic framework that validates abstract free-form hypotheses by iteratively designing and executing specific falsification experiments while maintaining strict Type-I error control via e-values.
Core Problem
Validating abstract natural language hypotheses is difficult because they cannot be tested directly, and LLM-generated hypotheses are voluminous and prone to hallucination.
Why it matters:
- Directly verifying broad statements like 'Gene X causes Disease Y' is infeasible; they must be translated into measurable implications
- Without rigorous statistical control, automated systems risk high Type-I error rates (false discoveries), wasting resources on incorrect theories
- Existing LLM agents lack mechanisms to aggregate evidence from multiple tests while preserving statistical validity
Concrete Example:
For the hypothesis 'Gene ZAP70 regulates IL-2 production', a standard agent might find a single correlation in a dataset and falsely claim verification. POPPER instead sequentially tests distinct implications (e.g., protein interactions, then tissue expression correlations, then eQTL associations), aggregating evidence to avoid false positives.
Key Novelty
Agentic Sequential Falsification with E-values
- Adopts Karl Popper's falsification principle: instead of proving a hypothesis, the system iteratively attempts to refute specific sub-hypotheses (measurable implications) derived from the main claim
- Uses a sequential testing framework based on e-values (rather than p-values) to aggregate evidence from dependent, adaptively chosen experiments, allowing optional stopping while controlling Type-I error
Architecture
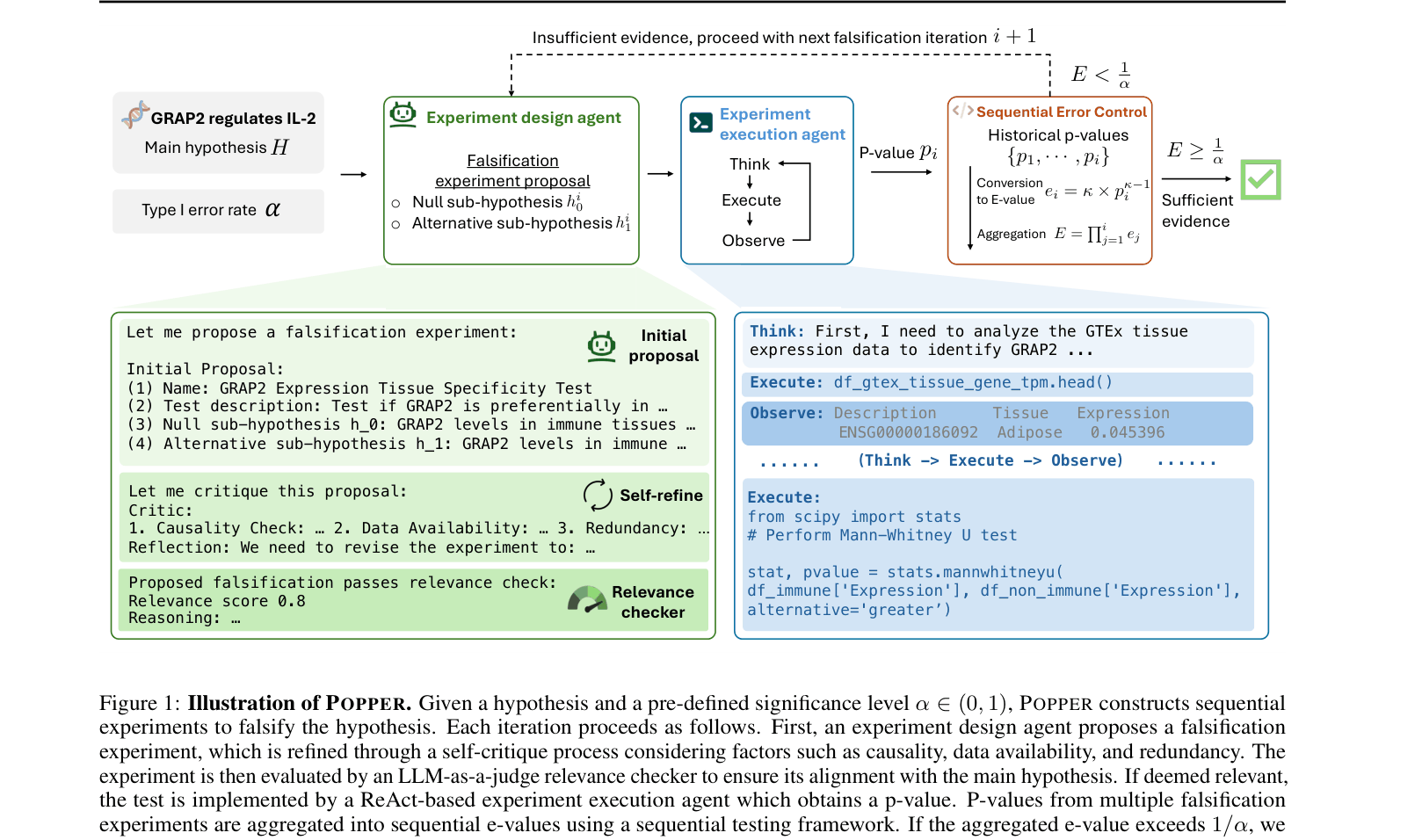
The iterative workflow of POPPER for hypothesis validation.
Evaluation Highlights
- Maintains Type-I error ≤ 0.1 across biology and sociology benchmarks, whereas standard LLM agents (CodeGen, ReAct) fail (errors up to 0.248)
- Achieves 63.8% power on DiscoveryBench, outperforming ReAct (38.3%) and CodeGen (37.8%) by substantial margins while maintaining validity
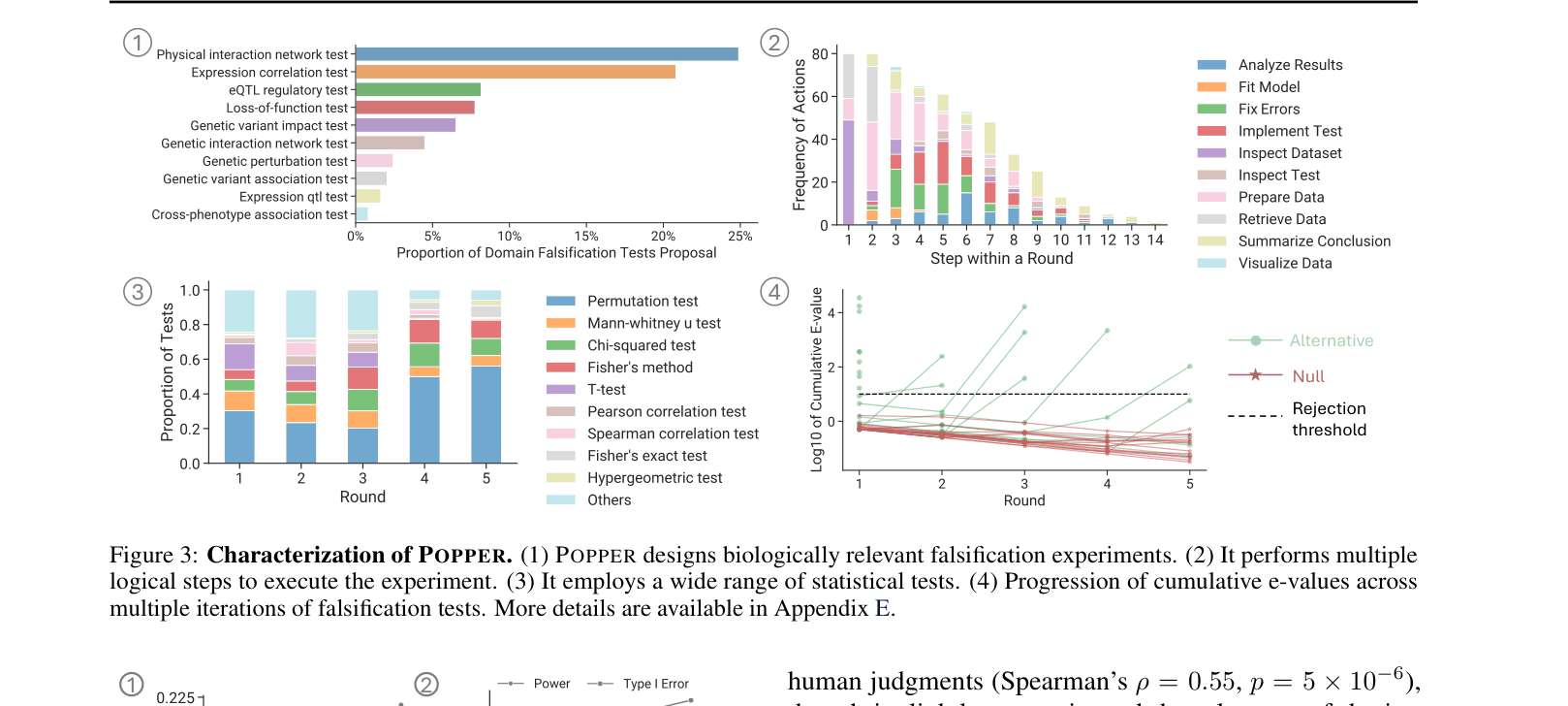
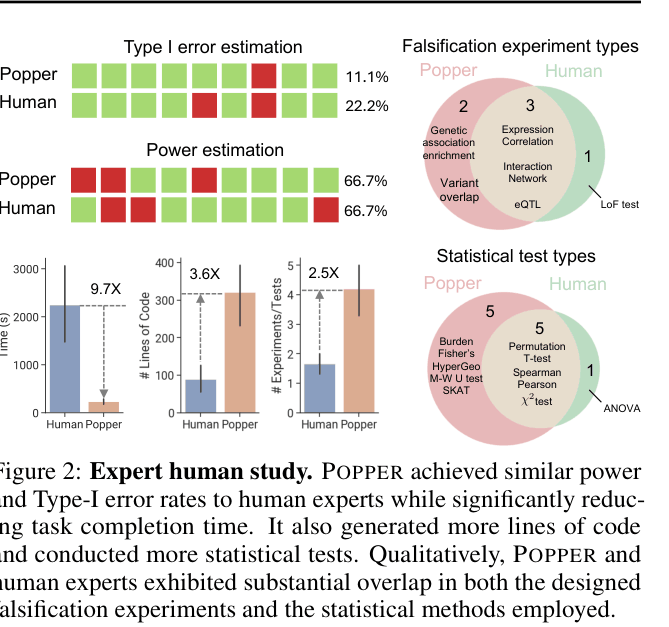
- Matches human expert performance in error control and power on biological tasks but completes validation 9.7x faster
Breakthrough Assessment
9/10
Significantly advances automated science by solving the critical problem of statistical rigor in LLM agents. The integration of e-values with agentic reasoning is a methodological leap for reliable discovery.