📝 Paper Summary
Benchmark datasets
Factuality
Modularized RAG pipeline
NEOQA is a benchmark of fictional news timelines and questions designed to force LLMs to reason solely from retrieved evidence rather than parametric memory, exposing reliance on shortcuts.
Core Problem
RAG benchmarks quickly become stale as newer LLMs internalize the test data's facts during pre-training, making it impossible to distinguish genuine retrieval-based reasoning from simple memory recall.
Why it matters:
- Trustworthy RAG systems must ground answers in provided documents, not hallucinate from outdated or irrelevant internal knowledge
- Existing benchmarks fail to penalize 'shortcut reasoning' where models guess answers without sufficient evidence because the facts are known to them
- Current evaluation methods cannot accurately measure a model's ability to deflect (refuse to answer) when evidence is genuinely insufficient
Concrete Example:
In RealTimeQA, GPT-4 Turbo answers older questions correctly without any documents because it memorized the news. In NEOQA, answering 'What did Selvia Renek question about the certification program?' requires combining two fictional documents; if one is missing, the model must deflect, but models often halluncinate an answer anyway.
Key Novelty
Fictional World Generation for Clean RAG Evaluation
- Generates entirely fictional timelines of events and named entities using GPT-4o to ensure no pre-training data contamination exists
- Constructs 'parallel worlds' that follow physical laws but contain unique facts, forcing models to rely exclusively on provided context
- Automatically generates pairs of questions and evidence sets that are explicitly sufficient, insufficient, or misleading to test precise reasoning boundaries
Architecture
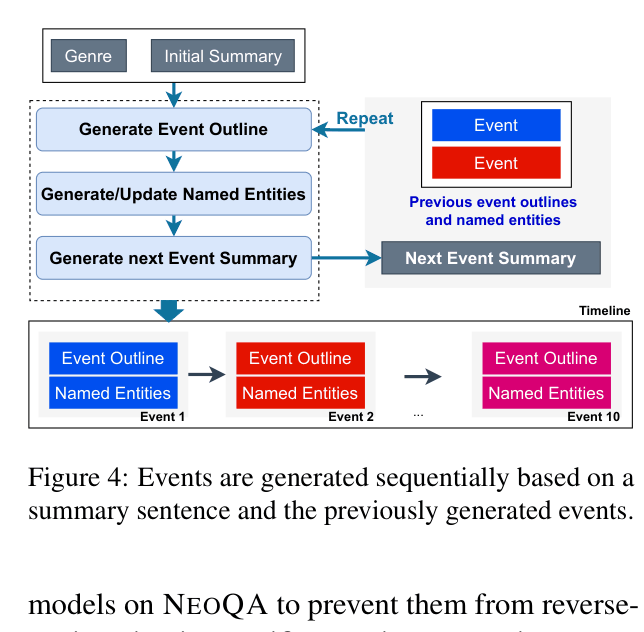
The iterative process for generating the fictional timeline.
Evaluation Highlights
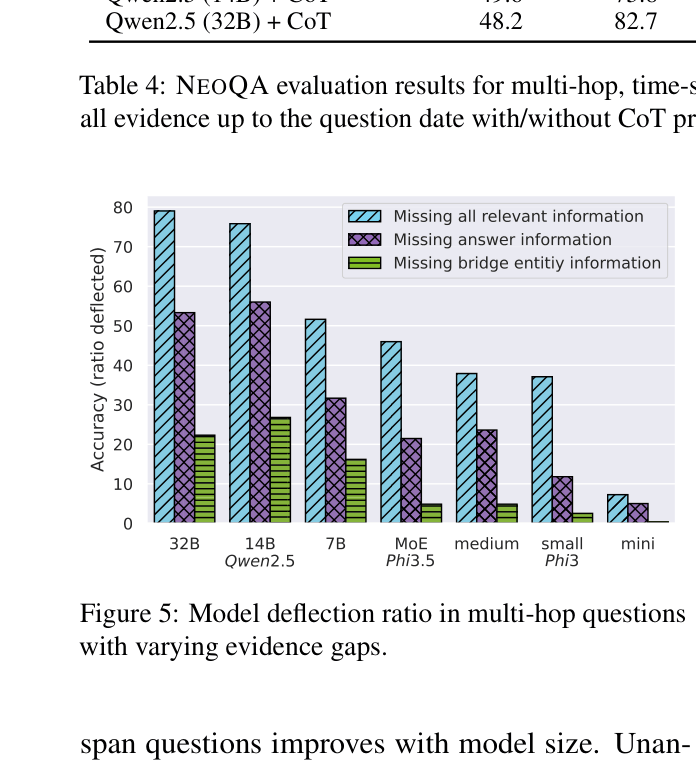
- Models struggle significantly with 'insufficient evidence' scenarios: Phi3-mini achieves only 3.1% accuracy on multi-hop questions where bridge entities are missing, failing to deflect.
- Larger models (Qwen2.5-32B) perform better overall (ADTScore 53.2) but still fail to detect subtle false premises, scoring only 26.7% on 'False Premise' questions.
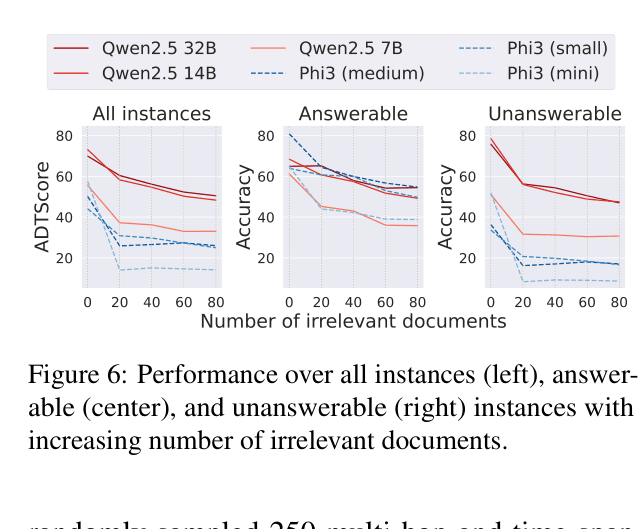
- Performance drops sharply as irrelevant documents increase: accuracy on answerable questions falls by ~20% for smaller models when 20 distractor documents are added.
Breakthrough Assessment
8/10
A highly necessary methodological shift for RAG evaluation. By effectively 'sanitizing' the knowledge cutoff problem via fiction, it offers a more rigorous test of reasoning than real-world datasets.