📝 Paper Summary
LLM Reasoning
Agentic AI
Inference Scaling
This survey unifies recent LLM reasoning advances into a two-dimensional framework: regimes (inference scaling vs. learning-to-reason) and architectures (standalone LLMs vs. agentic systems).
Core Problem
Rapid progress in LLM reasoning has fragmented into disconnected subfields (like inference scaling vs. training), lacking a unified framework to connect standalone models with emerging agentic workflows.
Why it matters:
- Reasoning distinguishes advanced AI (AGI-bound) from basic chatbots, yet scaling pre-training alone has hit diminishing returns for complex logic.
- Prior surveys focus narrowly on either prompting or agents, missing the critical transition from inference-time compute (e.g., o1) to learning-to-reason (e.g., R1).
- Researchers need a structured map to navigate the shift from static models to dynamic, multi-step agentic systems involving tools and multi-agent collaboration.
Concrete Example:
Traditional CoT prompting (standalone inference) fails on complex tasks like 'Deep Research' requiring web browsing. The survey contrasts this with agentic workflows (like OpenAI Deep Research) that iterate through perception and action, showing how they differ structurally yet share underlying optimization principles.
Key Novelty
Orthogonal Taxonomy of Reasoning Frontiers
- Categorizes methods by **Regime** (when reasoning happens: inference-time search vs. training-time RL) and **Architecture** (component structure: standalone LLM vs. single/multi-agent systems).
- Unifies diverse techniques under **Input/Output** perspectives: prompt engineering aligns with agent perception/communication, while candidate refinement aligns with agent action/coordination.
Architecture
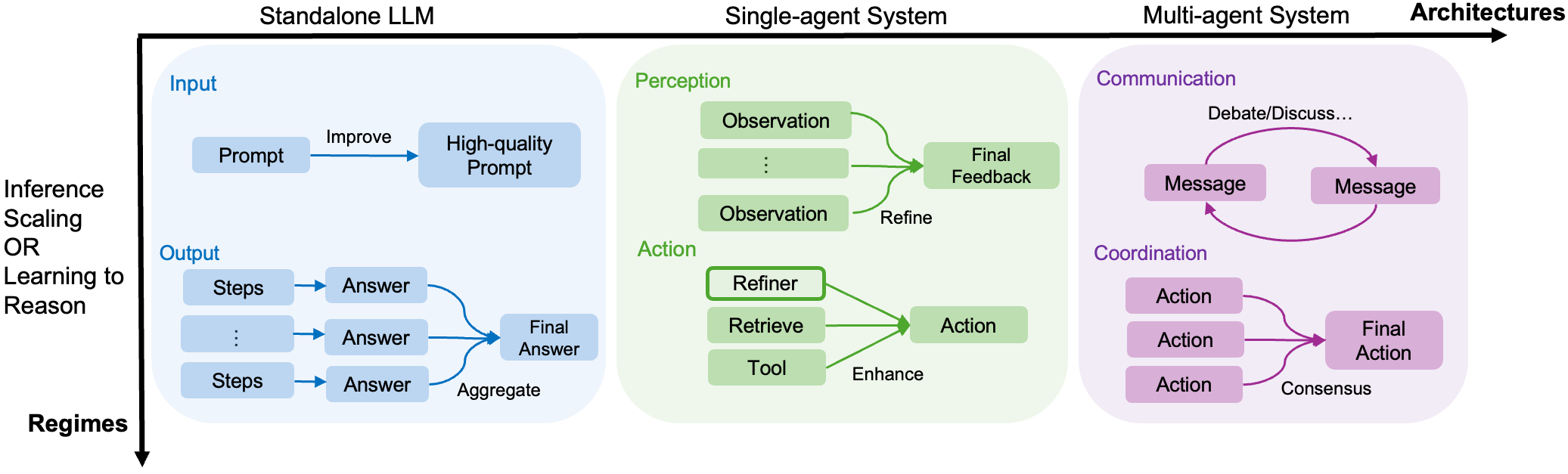
A unified perspective of the survey's categorization, mapping 'Input' and 'Output' concepts across Standalone LLMs, Single-Agent Systems, and Multi-Agent Systems.
Breakthrough Assessment
9/10
This is a timely, foundational survey that provides the first comprehensive taxonomy connecting the explosion of recent reasoning models (o1, DeepSeek-R1) with agentic systems.