📝 Paper Summary
Context Optimization
Self-Improving Agents
LLM Memory
ACE treats context as an evolving, itemized playbook managed by specialized agents (Generator, Reflector, Curator) to accumulate detailed strategies without the information loss caused by iterative rewriting.
Core Problem
Current context adaptation methods suffer from brevity bias (optimizing for short, generic prompts) and context collapse (iterative rewriting by LLMs erases critical details over time).
Why it matters:
- Agents and domain-specific tasks (e.g., finance) require accumulating detailed, comprehensive heuristics rather than concise summaries
- Iterative rewriting methods like Reflexion or Dynamic Cheatsheet often degrade performance in long horizons by compressing away necessary knowledge
- Monolithic context regeneration is computationally expensive and high-latency for real-time applications
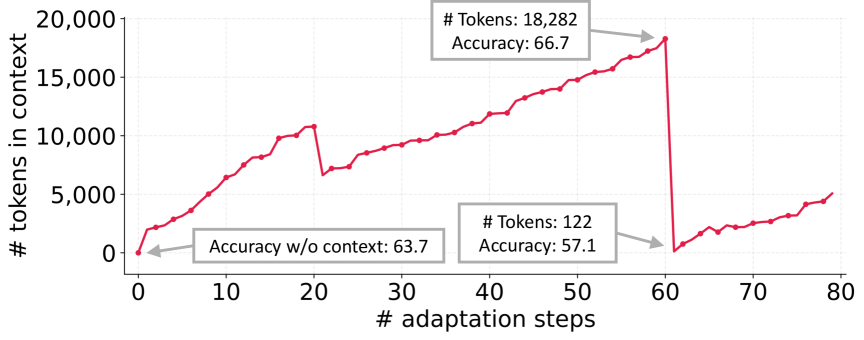
Concrete Example:
In AppWorld, a context at step 60 contained ~18k tokens with 66.7% accuracy. The next update collapsed it to 122 tokens, dropping accuracy to 57.1%—worse than the unadapted baseline.
Key Novelty
Agentic Context Engineering (ACE)
- Treats context as a collection of structured 'bullets' (metadata + content) rather than a monolithic text block, allowing granular management
- Decomposes adaptation into three roles: Generator (acts), Reflector (extracts lessons), and Curator (formats lessons), preventing the bottleneck of a single model doing everything
- Uses 'Delta Updates' to append small batches of insights and a deterministic 'Grow-and-Refine' mechanism to merge/deduplicate, avoiding the variance of full LLM rewrites
Architecture
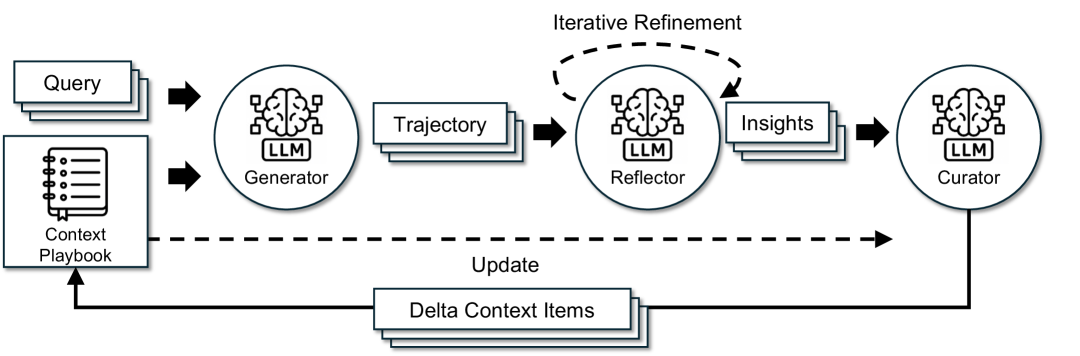
The agentic workflow of ACE, showing the interaction between the Generator, Reflector, Curator, and the Context Storage
Evaluation Highlights
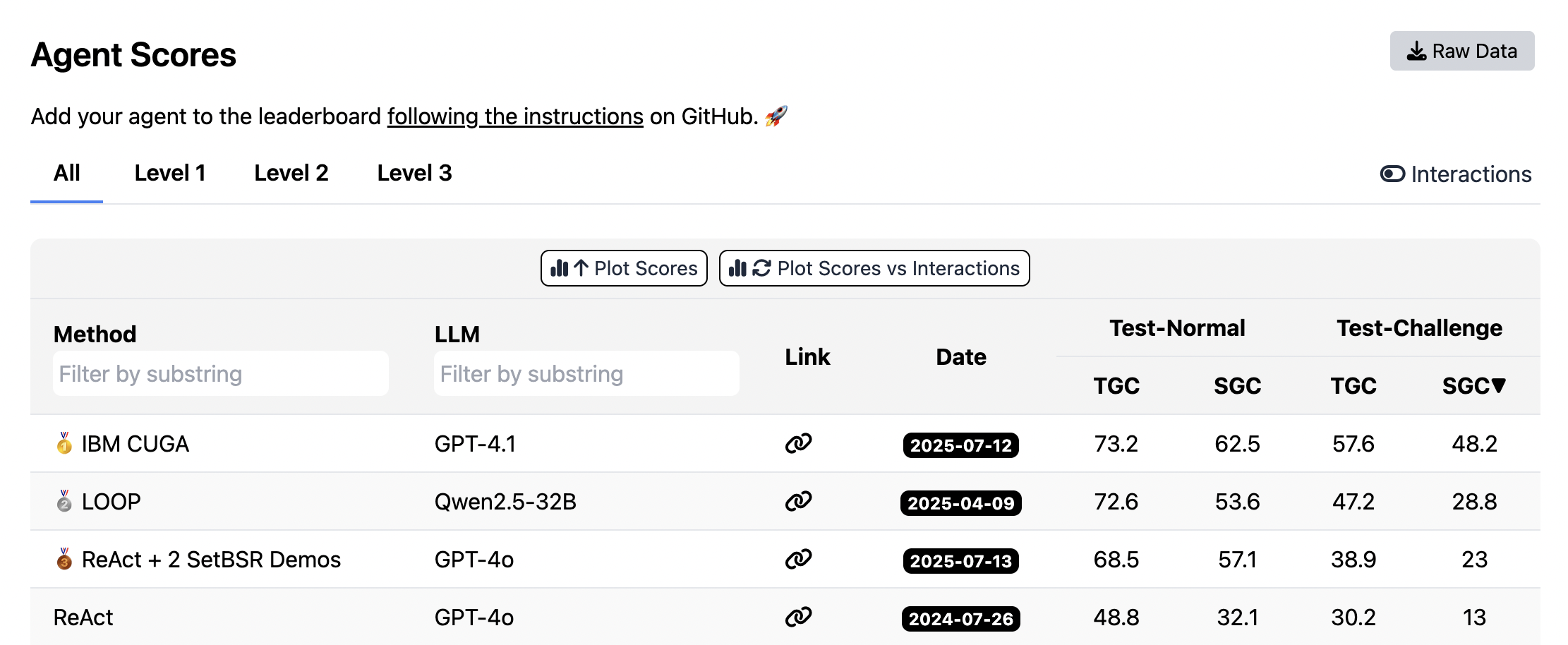
- Matches top-ranked IBM-CUGA (GPT-4.1) on AppWorld leaderboard using the smaller DeepSeek-V3.1, surpassing it by +8.4% on the 'test-challenge' split
- +10.6% average gain on agent benchmarks and +8.6% on financial benchmarks compared to strong baselines like GEPA and Dynamic Cheatsheet
- Reduces adaptation latency by 86.9% on average compared to GEPA by using incremental delta updates instead of full context rewrites
Breakthrough Assessment
9/10
Addresses the fundamental 'context collapse' problem in self-improving agents. Achieving SOTA results with open-weights models against GPT-4 competitors while drastically cutting latency is a significant practical breakthrough.